With the enhanced exploration of the new generation of the web, people are free to state their opinion on any particular topic like product, services, organization and even on other people online in different social media platform and thus an innumerous amount of user generated contents are being created each moment. Hence, the need for mining this information has become the priority of the researcher so that they can identify the user’s sentiments and guide other people in various fields. Sentiment analysis deals with analyzing the review, opinion, attitude and emotions of a person from a given set of text by categorizing those on the basis of polarity as positive, negative and neutral. In this paper, sentiment of the social media text in Assamese Language is being analyzed because most of the communication is done through regional language and as a researcher from this region it is utmost concern to mine this information. To analyze the sentiments from the manually prepared datasets, LSTM- deep learning algorithm is used and implemented it in Python environment and also overall performance is measured in terms of accuracy, precision, recall and f1-score.
| Published in | American Journal of Computer Science and Technology (Volume 7, Issue 2) |
| DOI | 10.11648/j.ajcst.20240702.11 |
| Page(s) | 29-37 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2024. Published by Science Publishing Group |
Sentiment Analysis, NLP, Deep Learning, LSTM
2.2. Sentiment Analysis Levels Types
2.3. Sentiment Analysis Approaches
2.4. Deep Learning
2.5. LSTM (Long-Short Term Memory)
2.6. Bidirectional LSTM
Correct label | |||
|---|---|---|---|
Positive | Negative | ||
Predicted label | Positive | TP (True Positive) | FP (False Positive) |
Negative | FN (False Negative) | TN (True Negative) | |
4.1. Experimental Results
4.2. Result Analysis
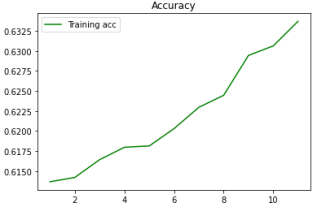
Iterations | Accuracy | Loss |
|---|---|---|
1 | 0.6142 | 0.9020 |
2 | 0.6173 | 0.8942 |
3 | 0.6179 | 0.8886 |
4 | 0.6182 | 0.8821 |
5 | 0.6211 | 0.8739 |
6 | 0.6251 | 0.8684 |
7 | 0.6271 | 0.8627 |
8 | 0.6308 | 0.8573 |
9 | 0.6322 | 0.8544 |
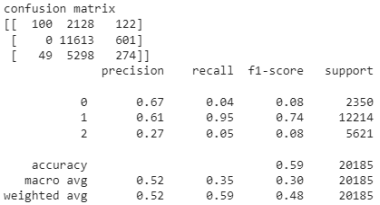
precision | recall | f1-score | |
|---|---|---|---|
0 | 0.67 | 0.04 | 0.08 |
1 | 0.61 | 0.95 | 0.74 |
2 | 0.27 | 0.05 | 0.08 |
Accuracy | 0.59 |
5.1. Conclusion
5.2. Future Works
| [1] | Bo Pang and Lillian Lee, Shivakumar Vaithyanathan, "Thumbs up? Sentiment Classification using Machine Learning Techniques", Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Philadelphia, July 2002, pp. 79-86. |
| [2] | Rudy Prabowo, Mike Thelwall, “Sentiment Analysis: A Combined Approach”. |
| [3] | Betül AyKaraku¸ Muhammed Talo, ̇IbrahimRızaHalla, GalipAydin, “Evaluating deep learning models for sentiment classification”. |
| [4] | Dr. G. S. N. Murthy, Shanmukha Rao Allu, Bhargavi Andhavarapu, Mounika Bagadi, Mounika Belusonti, “Text based Sentiment Analysis using LSTM”, International Journal of Engineering Research & Technology (IJERT) ISSN: 2278-0181, May-2020. |
| [5] | Hanane Elfaik and El Habib Nfaoui, “Deep Bidirectional LSTM Network Learning-Based Sentiment Analysis for Arabic Text”. |
| [6] | Wisam Hazım Gwad Gwad, Imad Mahmood Ismael Ismael, Yasemin Gültepe, “Twitter Sentiment Analysis Classification in the Arabic Language using Long Short-Term Memory Neural Networks”, International Journal of Engineering and Advanced Technology (IJEAT) ISSN: 2249–8958, Volume-9 Issue-3, February, 2020. |
| [7] | S. Sachin Kumar (B), M. Anand Kumar, and K. P. Soman, “Sentiment Analysis of Tweets in Malayalam Using Long Short-Term Memory Units and Convolutional Neural Nets”, January 2017. |
| [8] | Sonali Rajesh Shah, Abhishek Kaushik, “SENTIMENT ANALYSIS ON INDIAN INDIGENOUS LANGUAGES: A REVIEW ON MULTILINGUAL OPINION MINING”, November 26, 2019. |
| [9] | Abhishek Bhagat, Akash Sharma, Sarat Kr. Chettri, “Machine Learning Based Sentiment Analysis for Text Messages”, IJCAT - International Journal of Computing and Technology, Volume 7, Issue 6, June 2020 ISSN (Online): 2348-6090. |
| [10] | Soe Yu Maw, May Aye Khine, "Aspect based Sentiment Analysis for travel and tourism in Myanmar Language using LSTM". |
| [11] | Subarno Pal, Dr. Soumadip Ghosh, Dr. Amitava Nag, “Sentiment Analysis in the light of LSTM Recurrent Neural Networkss”, International Conference on Information Technology and Applied Mathematics, 2017. |
APA Style
Talukdar, M., Sarma, S. K. (2024). Bidirectional LSTM-based Sentiment Analysis for Assamese Text. American Journal of Computer Science and Technology, 7(2), 29-37. https://doi.org/10.11648/j.ajcst.20240702.11
ACS Style
Talukdar, M.; Sarma, S. K. Bidirectional LSTM-based Sentiment Analysis for Assamese Text. Am. J. Comput. Sci. Technol. 2024, 7(2), 29-37. doi: 10.11648/j.ajcst.20240702.11
@article{10.11648/j.ajcst.20240702.11,
author = {Manashi Talukdar and Shikhar Kumar Sarma},
title = {Bidirectional LSTM-based Sentiment Analysis for Assamese Text
},
journal = {American Journal of Computer Science and Technology},
volume = {7},
number = {2},
pages = {29-37},
doi = {10.11648/j.ajcst.20240702.11},
url = {https://doi.org/10.11648/j.ajcst.20240702.11},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ajcst.20240702.11},
abstract = {With the enhanced exploration of the new generation of the web, people are free to state their opinion on any particular topic like product, services, organization and even on other people online in different social media platform and thus an innumerous amount of user generated contents are being created each moment. Hence, the need for mining this information has become the priority of the researcher so that they can identify the user’s sentiments and guide other people in various fields. Sentiment analysis deals with analyzing the review, opinion, attitude and emotions of a person from a given set of text by categorizing those on the basis of polarity as positive, negative and neutral. In this paper, sentiment of the social media text in Assamese Language is being analyzed because most of the communication is done through regional language and as a researcher from this region it is utmost concern to mine this information. To analyze the sentiments from the manually prepared datasets, LSTM- deep learning algorithm is used and implemented it in Python environment and also overall performance is measured in terms of accuracy, precision, recall and f1-score.
},
year = {2024}
}
TY - JOUR T1 - Bidirectional LSTM-based Sentiment Analysis for Assamese Text AU - Manashi Talukdar AU - Shikhar Kumar Sarma Y1 - 2024/04/28 PY - 2024 N1 - https://doi.org/10.11648/j.ajcst.20240702.11 DO - 10.11648/j.ajcst.20240702.11 T2 - American Journal of Computer Science and Technology JF - American Journal of Computer Science and Technology JO - American Journal of Computer Science and Technology SP - 29 EP - 37 PB - Science Publishing Group SN - 2640-012X UR - https://doi.org/10.11648/j.ajcst.20240702.11 AB - With the enhanced exploration of the new generation of the web, people are free to state their opinion on any particular topic like product, services, organization and even on other people online in different social media platform and thus an innumerous amount of user generated contents are being created each moment. Hence, the need for mining this information has become the priority of the researcher so that they can identify the user’s sentiments and guide other people in various fields. Sentiment analysis deals with analyzing the review, opinion, attitude and emotions of a person from a given set of text by categorizing those on the basis of polarity as positive, negative and neutral. In this paper, sentiment of the social media text in Assamese Language is being analyzed because most of the communication is done through regional language and as a researcher from this region it is utmost concern to mine this information. To analyze the sentiments from the manually prepared datasets, LSTM- deep learning algorithm is used and implemented it in Python environment and also overall performance is measured in terms of accuracy, precision, recall and f1-score. VL - 7 IS - 2 ER -
Information Technology, Gauhati University, Guwahati, India
Information Technology, Gauhati University, Guwahati, India

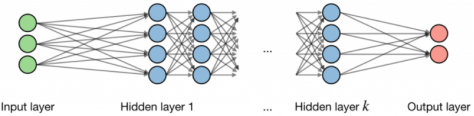
Figure 1. Working of Neural Network.

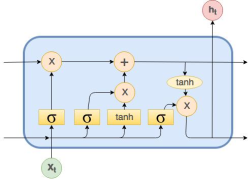
Figure 2. Single LSTM cell.

Figure 3. Bidirectional LSTM.

Figure 4. Flowchart of the methodology used.

Figure 5. Training and test data in the dataset.

Figure 6. Training accuracy and loss.

Figure 7. Confusion matrix.

Figure 8. Training accuracy.

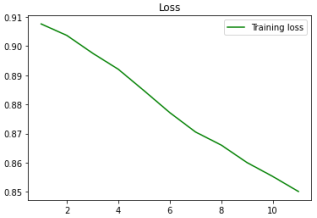
Figure 9. Training loss.

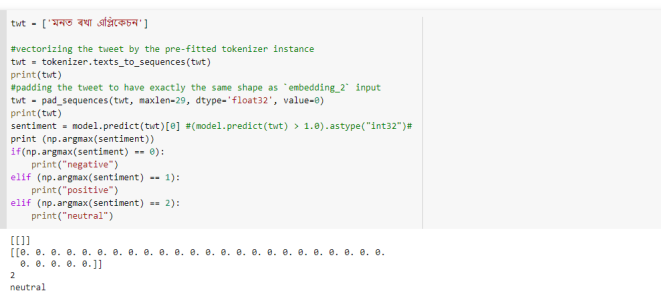
Figure 10. Result of Test data 1.

Figure 11. Result of Test data 2.
Information