Four linear multilevel mixed-risk models were compared using model assumption tests and predictions. Models varied by the number of random intercepts from 1 to 4, producing 2-level through 5-level models of the same measure, operative time. Normality of the dependent variable and residuals, variance homoscedasticity, level-1, and level-2 exogeneity were tested using the robust test of the level-1 residuals variance by surgeon, estimates of density, skew, and the Hausman test. Measure (operative time by hospital and surgeon) aberrancy and risk classification were evaluated using traditional methods and used to assess distribution measures. The dependent variable and the level-1 residuals required transformation for linearity and variance stabilization, respectively. Normality criteria were met for both level-1 and level-2 residuals and standardized residuals. The likelihood ratio comparing the four models was significantly larger for the 5-level (1016.1; P<0.00005) model than the likelihood ratio for the four-level and other models. Shrinkage was greatest for the 2-level model (0.039; P<0.00005) and least for the 5-level model (0.028; P<0.00005). Level-1 variance homoscedasticity was confirmed by the robust variance test across all models (P>F=1). Aberrant value detection did not require the exclusion of any observations, while prediction intervals revealed low or high risk for 54.2% of surgeons for the 2-level model and 8.6% for the 5-level model. The traditional (c2 = -11.01; P=1) and instrumental variable (c2 = 21.06; P=1) Hausman tests show that the null hypothesis cannot be rejected for level-1 or level-2 exogeneity. Once level-1 and level-2 exogeneity was confirmed, and since deconfounding was a model consideration, causal inferential capacity was assumed. The likelihood ratio, residual variance, shrinkage, and predictions show that the 5-level model is preferred to the other models.
| Published in | American Journal of Theoretical and Applied Statistics (Volume 13, Issue 2) |
| DOI | 10.11648/j.ajtas.20241302.11 |
| Page(s) | 29-38 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2024. Published by Science Publishing Group |
Misclassification, Assumption/Specification Tests, Multi-level Mixed Effects Model, Random Intercept, Confounding, Causal
2.1. Model Fitting
2.2. Testing Model Assumptions
3.1. Likelihood Ratio Comparison
Model | Compared to OLS | Compared to the nested multilevel model |
|---|---|---|
2-level | 7305.8* | |
3-level | 7437.7* | 2-level = 132* |
4-level | 10060.4* | 3-level = 2622.6* |
5-level | 11076.5* | 4-level = 1016.1* |
3.2. Comparison of Maximum Likelihood, Empirical Bayesian Random Intercepts, and Shrinkage factors
Model | Mean difference ML - EB | lower confidence limit | upper confidence limit | t-test ML - EB | Pr (T>t) | Shrinkage factor |
|---|---|---|---|---|---|---|
2-level | 0.039 | 0.033 | 0.045 | 12.7 | 0.0000 | 0.863 |
3-level | 0.036 | 0.03 | 0.041 | 13.6 | 0.0000 | 0.845 |
4-level | 0.029 | 0.025 | 0.034 | 12.5 | 0.0000 | 0.852 |
5-level | 0.028 | 0.023 | 0.032 | 12.2 | 0.0000 | 0.856 |
3.3. Assess for Homoscedasticity of Level-1 Residuals
Model | W50 | W10 |
|---|---|---|
2-level | 0.46; P>F=1 | 0.47; P>F=1 |
3-level | 0.41; P>F=1 | 0.51; P>F=1 |
4-level | 0.49; P>F=1 | 0.49; P>F=1 |
5-level | 0.57; P>F=1 | 0.90; P>F=1 |
3.4. Normality Testing
3.5. Testing for Cluster Aberrancy
3.6. Exogeneity Confirmation
3.7. Classification of Risk
3.8. Causal Interpretation and Deconfounding
| [1] | Ruppert, D., M. P. Wand, and R. J. Carroll. 2003. Semiparametric Regression. Cambridge: Cambridge University Press. |
| [2] | Rabe-Hesketh, S., and A. Skrondal. 2022. Multilevel and Longitudinal Modeling Using Stata. 4th ed. College Station, TX: Stata Press. Based on: J. Martin Bland, Douglas G. Altman. Statistical Methods for Assessing Agreement Between Two Methods of Clinical Measurement. Lancet, 1986; i: 307-310. |
| [3] | Cecil W. T., Selection of Reliable and Valid Surgeon Performance Measures, American Journal of Management Science and Engineering. Volume 5, Issue 5, September 2020, pp. 62-69. |
| [4] | Hannan, Ph. D., E. L., Kilburn, Jr, MA, H., O'Donnell, MA, MS, J. F., Lukacik, MA, G., & Shields, E. (1990). Adult Open Heart Surgery in New York State: An Analysis of Risk Factors and Hospital Mortality Rates. JAMA, 2768 - 2774. |
| [5] | David M. Shahian, Sharon-Lise Normand, David F. Torchiana, Stanley M. Lewis, John O. Pastore, Richard E. Kuntz, Paul I. Dreyer, Cardiac surgery report cards: comprehensive review and statistical critique. This review is an abridged version of a report submitted by the Massachusetts Cardiac Care Quality Commission to the Massachusetts Legislature, May 2001., The Annals of Thoracic Surgery, Volume 72, Issue 6, 2001, Pages 2155-2168, ISSN 0003-4975, |
| [6] | Daley BJ, Cecil W, Clarke PC, Cofer JB, Guillamondegui OD. How slow is too slow? Correlation of operative time to complications: an analysis from the Tennessee Surgical Quality Collaborative. J Am Coll Surg. 2015 Apr; 220(4): 550-8. |
| [7] | Maruthappu, M., Duclos, A., Lipsitz, S. R., Orgill, D., & Carty, M. J. (2015). Surgical learning curves and operative efficiency: A cross-specialty observational study. BMJ Open, 5(3). |
| [8] | StataCorp. 2021. Stata Statistical Software: Release 17. College Station, TX: StataCorp LLC. |
| [9] | Brown, M. B., and A. B. Forsythe. 1974. Robust tests for the equality of variances. Journal of the American Statistical Association 69: 364–367. |
| [10] | Altman, Douglas G. and Bland, Martin J. The normal distribution. British Medical Journal, 310: 298. February 4, 1995. |
| [11] | Wooldridge, Jeffrey M., (2012). Introductory econometrics: a modern approach. Mason, Ohio: South-Western Cengage Learning. |
| [12] | Bland, M. (2015). An Introduction to Medical Statistics (4th ed.). Oxford: Oxford University Press. |
| [13] | Hausman, J. A. 1978. Specification tests in econometrics. Econometrica 46: 1251–1271. |
| [14] | Greene, W. (2018) Econometric Analysis. 8th Edition, Pearson Education Limited, London. |
| [15] | Clayton, D. G., and M. Hills. 1993. Statistical Models in Epidemiology. Oxford: Oxford University Press. |
| [16] | Pearl J. Causality: Models, Reasoning, and Inference. Cambridge University Press, second edition, (2009). |
APA Style
Cecil, W. T. (2024). The Distribution of Risk Across Healthcare Providers and Reducing Misclassification. American Journal of Theoretical and Applied Statistics, 13(2), 29-38. https://doi.org/10.11648/j.ajtas.20241302.11
ACS Style
Cecil, W. T. The Distribution of Risk Across Healthcare Providers and Reducing Misclassification. Am. J. Theor. Appl. Stat. 2024, 13(2), 29-38. doi: 10.11648/j.ajtas.20241302.11
AMA Style
Cecil WT. The Distribution of Risk Across Healthcare Providers and Reducing Misclassification. Am J Theor Appl Stat. 2024;13(2):29-38. doi: 10.11648/j.ajtas.20241302.11
@article{10.11648/j.ajtas.20241302.11,
author = {William Thomas Cecil},
title = {The Distribution of Risk Across Healthcare Providers and Reducing Misclassification
},
journal = {American Journal of Theoretical and Applied Statistics},
volume = {13},
number = {2},
pages = {29-38},
doi = {10.11648/j.ajtas.20241302.11},
url = {https://doi.org/10.11648/j.ajtas.20241302.11},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ajtas.20241302.11},
abstract = {Four linear multilevel mixed-risk models were compared using model assumption tests and predictions. Models varied by the number of random intercepts from 1 to 4, producing 2-level through 5-level models of the same measure, operative time. Normality of the dependent variable and residuals, variance homoscedasticity, level-1, and level-2 exogeneity were tested using the robust test of the level-1 residuals variance by surgeon, estimates of density, skew, and the Hausman test. Measure (operative time by hospital and surgeon) aberrancy and risk classification were evaluated using traditional methods and used to assess distribution measures. The dependent variable and the level-1 residuals required transformation for linearity and variance stabilization, respectively. Normality criteria were met for both level-1 and level-2 residuals and standardized residuals. The likelihood ratio comparing the four models was significantly larger for the 5-level (1016.1; PF=1). Aberrant value detection did not require the exclusion of any observations, while prediction intervals revealed low or high risk for 54.2% of surgeons for the 2-level model and 8.6% for the 5-level model. The traditional (c2 = -11.01; P=1) and instrumental variable (c2 = 21.06; P=1) Hausman tests show that the null hypothesis cannot be rejected for level-1 or level-2 exogeneity. Once level-1 and level-2 exogeneity was confirmed, and since deconfounding was a model consideration, causal inferential capacity was assumed. The likelihood ratio, residual variance, shrinkage, and predictions show that the 5-level model is preferred to the other models.
},
year = {2024}
}
TY - JOUR T1 - The Distribution of Risk Across Healthcare Providers and Reducing Misclassification AU - William Thomas Cecil Y1 - 2024/04/29 PY - 2024 N1 - https://doi.org/10.11648/j.ajtas.20241302.11 DO - 10.11648/j.ajtas.20241302.11 T2 - American Journal of Theoretical and Applied Statistics JF - American Journal of Theoretical and Applied Statistics JO - American Journal of Theoretical and Applied Statistics SP - 29 EP - 38 PB - Science Publishing Group SN - 2326-9006 UR - https://doi.org/10.11648/j.ajtas.20241302.11 AB - Four linear multilevel mixed-risk models were compared using model assumption tests and predictions. Models varied by the number of random intercepts from 1 to 4, producing 2-level through 5-level models of the same measure, operative time. Normality of the dependent variable and residuals, variance homoscedasticity, level-1, and level-2 exogeneity were tested using the robust test of the level-1 residuals variance by surgeon, estimates of density, skew, and the Hausman test. Measure (operative time by hospital and surgeon) aberrancy and risk classification were evaluated using traditional methods and used to assess distribution measures. The dependent variable and the level-1 residuals required transformation for linearity and variance stabilization, respectively. Normality criteria were met for both level-1 and level-2 residuals and standardized residuals. The likelihood ratio comparing the four models was significantly larger for the 5-level (1016.1; PF=1). Aberrant value detection did not require the exclusion of any observations, while prediction intervals revealed low or high risk for 54.2% of surgeons for the 2-level model and 8.6% for the 5-level model. The traditional (c2 = -11.01; P=1) and instrumental variable (c2 = 21.06; P=1) Hausman tests show that the null hypothesis cannot be rejected for level-1 or level-2 exogeneity. Once level-1 and level-2 exogeneity was confirmed, and since deconfounding was a model consideration, causal inferential capacity was assumed. The likelihood ratio, residual variance, shrinkage, and predictions show that the 5-level model is preferred to the other models. VL - 13 IS - 2 ER -
Independent Consultant, Knoxville, United States

Figure 1. Normality testing of the observed and transformed operative time: Left panel kernel density estimates: untransformed (long dash-dot), transformed (solid line), and reference normal distribution (dash). Right panel normal quantile plot: reference normal (dash) and transformed (circles) showing that the reference normal quantile plot and the transformed value of operative time are nearly identical.
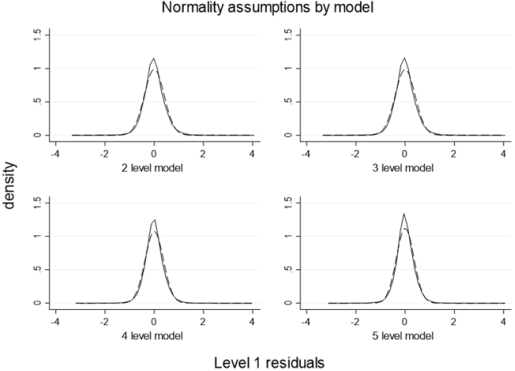
Figure 2. Level 1 residuals are estimated by comparing predicted and observed values. Normality is tested by comparing the densities of the observed and fitted values. These estimated values are represented by the solid line in the density plots above; the dashed line is the reference normal density. The observed densities show a slight skew (0.14 to 0.19).

Figure 3. Standardized level-1 residuals are the level-1 residuals (observed – predicted) multiplied by the inverse square root of the estimated error covariance matrix. Above, the standardized level-1 residuals are represented by the solid line, and the dashed line represents the reference normal distribution. The densities show a slight skew: 0.14 for the 5-level model, 0.15 for the 4-level model, and 0.19 for the two- and 3-level models. The formula for standardized residuals results in an asymptotic standard normal distribution.
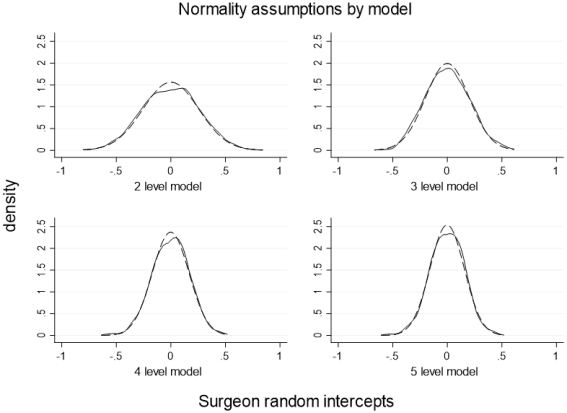
Figure 4. Random intercepts were created in each multilevel model for surgeons. The solid line above represents the observed surgeon random intercepts for each model, while the dashed line is the normal reference distribution. There is a slight skew: 0.05 for the 5-level model, 0.03 for the 4-level model, 0.25 for the 3-level model, and 0.18 for the 2-level model.
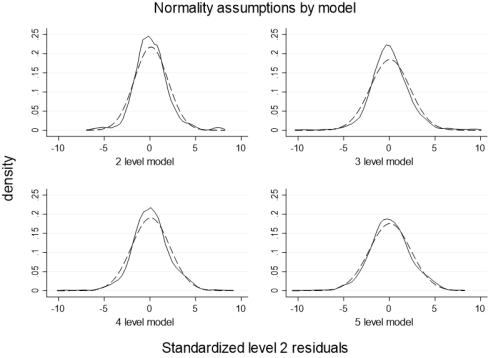
Figure 5. Standardized level 2 residuals are obtained by dividing the random intercepts by the diagnostic standard error; the densities show a slight skew of 0.14 for the 5-level model, 0.16 for the 4-level model, and 0.19 for both the two and 3-level models. The solid lines are the estimated residuals, and the dashed lines are the normal reference distribution.
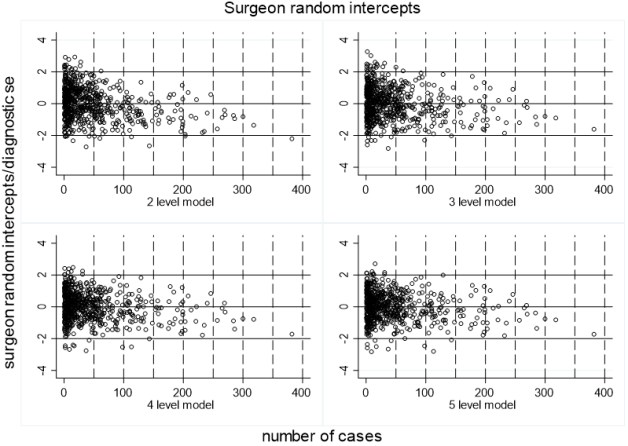
Figure 6. A score created by dividing the random intercepts by the diagnostic standard error aids aberrant value detection by surgeon cluster (each open circle), plotted on the vertical axis against the number of cases per cluster on the horizontal axis. Only 5% of the surgeon clusters should be larger than two dxse. The upper left panel for the 2-level model identifies 29 (4.87%) outlying clusters, and the upper right panel for the 3-level model also identifies twenty-nine outlying clusters. The lower left panel for the 4-level model and the lower right panel for the 5-level model identify 19 (3.2%) outlying clusters. Since there are no models with more than 5% of the random intercepts (surgeon clusters) as outlying, no cases require exclusion from analysis.
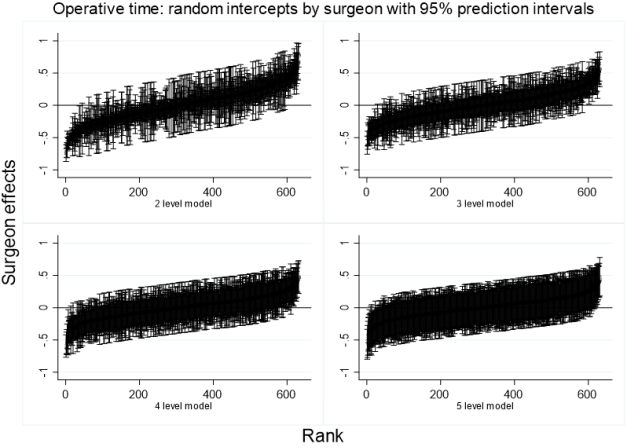
Figure 7. After excluding low reliability and aberrant values and based on random intercepts, the 2-level model caterpillar chart (upper left) identifies 172 surgeons that have a reduced risk of long-duration surgical procedures (LDP) and 151 with an elevated risk; 55% of 587 surgeons are identified as having either high or low risk. The 3-level model chart (upper right) identifies 120 surgeons with a reduced risk of long-duration procedures and 106 with an elevated risk of LDP (38.5%). The lower left chart, the 4-level model, identifies fifty-nine surgeons with a reduced risk of LDP and fifty with a high risk (18.6%). The 5-level model identifies thirty surgeons with a reduced risk of LDP and twenty-one with a high risk (8.7%). There are minor but significant differences in the rank-ordered slopes of the random intercepts shown in the figure above by model: 5-level 0.00085 (0.00082 – 0.00086); 4-level 0.0009005 (0.00087598 – 0.00093); 3-level 0.0011 (0.00106 – 0.0011); 2-level 0.00138 (0.00136 – 0.0014). Additionally, the median standard error of the random intercepts by model is different at 0.08 for the 2-level, 0.088 for the 3-level, 0.12 for the 4-level, and 0.145 for the 5-level model.
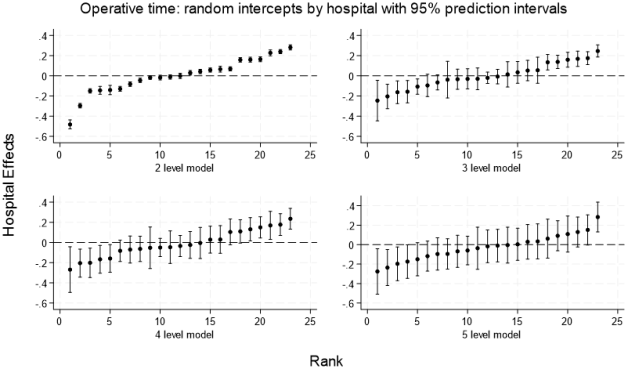
Figure 8. Classification of hospitals for operative time by model: 2 level model shows that 20 of 23 hospitals (87%) are classified as having high (11) or low risk (9) of a long-duration procedure; 3 level model 11 of 23 hospitals (47.8%) are classified as high (5) or low risk (6); 4 level model shows 10 of 23 hospitals (43.5%) are classified as high (5) or low risk (5) and the 5 level model shows 4 hospitals (17.4%) are classified as high (1) or low risk (3). Additionally, the median standard error of the random intercepts by model is different at 0.011 for the 2-level, 0.051 for the 3-level, 0.064 for the 4-level, and 0.085 for the 5-level model.
Information

