Abstract
Amid escalating global climate change and the pursuit of carbon-neutrality goals, carbon emission management and carbon footprint analysis have become central challenges in the green transition of the petroleum industry. Traditional carbon footprint accounting, however, is constrained by heterogeneous data sources, complex operational procedures, and high technical barriers for non-R&D personnel. To address these challenges, this paper proposes a lightweight multi-agent framework for oilfield carbon emission data analysis. Through natural-language interaction driven by LLM, the system integrates data access, a dual retrieval-augmented generation mechanism with Schema RAG and Document RAG, a Planner-Executor workflow, and automated report generation. Business personnel can complete intent parsing, SQL generation, statistical computation, chart rendering, and report composition through natural-language instructions. The framework is evaluated in real-world business scenarios across 13 oilfields, including basic query tasks, statistical analysis tasks, visualization generation tasks, report generation tasks, and multi-turn follow-up tasks. Experimental results show that the full system configuration, which combines Schema RAG, Planner-Executor, and Document RAG, increases the task completion rate to 93.3%, the SQL semantic consistency rate to 95.8%, and the visualization success rate to 100%, while also improving report quality and multi-turn interaction consistency. This framework lowers the technical barrier of complex data exploration, improves data processing efficiency, and provides a scalable and practical solution for the low-carbon digital transformation of the petroleum industry.
Keywords
Carbon Footprint Analysis, Multi-Agent System, Large Language Models, Retrieval-Augmented Generation, Text-to-SQL,
Petroleum Industry
1. Introduction
Amid escalating global climate change and the pursuit of carbon neutrality goals, carbon emission management and carbon footprint analysis represent core issues in the green transition of the petroleum industry
| [1] | IPCC. (2024). Task Force on National Greenhouse Gas Inventories. Intergovernmental Panel on Climate Change. Available from: https://www.ipcc.ch/working-group/tfi/ |
| [2] | World Resources Institute, & World Business Council for Sustainable Development. (2004). The Greenhouse Gas Protocol: A corporate accounting and reporting standard (Revised ed.). Available from: https://ghgprotocol.org/corporate-standard |
[1, 2]
. Production activities in the petroleum industry encompass exploration, development, transportation, processing, and consumption, which are characterized by long supply chains, multiple operational nodes, and complex emission sources
| [3] | International Organization for Standardization. (2006). ISO 14040: 2006 Environmental management — Life cycle assessment — Principles and framework.
Available from: https://www.iso.org/standard/37456.html |
| [4] | International Organization for Standardization. (2006). ISO 14044: 2006 Environmental management — Life cycle assessment — Requirements and guidelines.
Avaulable from: https://www.iso.org/standard/38498.html |
| [5] | Jamaludin, N. F., Shuhaimi, N. A., Mohamed, O. Y., & Hadipornama, M. F. (2023). Quantification of Carbon Footprint in Petroleum Refinery Process. Chemical Engineering Transactions, 106, 97-102. https://doi.org/10.3303/CET23106017 |
| [6] | Zhao, Hujie, Zhao, Dongfeng, Song, Qingbin, & Wang, Yongqiang. (2023). Identifying the spatiotemporal carbon footprint of the petroleum refining industry and its mitigation potential in China. Energy, 284, 129240.
https://doi.org/10.1016/j.energy.2023.129240 |
[3-6]
. Carbon footprint accounting serves as the foundation for enterprises to optimize emission reduction pathway
and directly influences the low-carbon transition of the industry and the effectiveness of national carbon management systems. With the continuous development of carbon markets and accounting standards, the efficient and accurate analysis of oilfield carbon emission data constitutes a critical engineering problem to address.
Currently, carbon footprint accounting in the petroleum industry involves high data processing complexity. Oilfield carbon emission data is primarily stored in a decentralized manner within heterogeneous tables
| [8] | Katsogiannis-Meimarakis, George, & Koutrika, Georgia. (2023). A survey on deep learning approaches for text-to-SQL. The VLDB Journal, 32(4), 905-936.
https://doi.org/10.1007/s00778-022-00776-8 |
| [9] | Hong, Zuyan, Yuan, Zheng, Zhang, Qiang, Chen, Hongyang, Dong, Junnan, Huang, Fei, & Huang, Xiao. (2024). Next-generation database interfaces: A survey of LLM-based text-to-SQL. arXiv preprint arXiv: 2406.08426.
https://doi.org/10.48550/arXiv.2406.08426 |
[8, 9]
. Different geographical blocks, products, and operational stages exhibit significant variations in data standards, field nomenclature, and table structures, which heavily increases the difficulty of data integration and comparative analysis. Business personnel frequently conduct queries and statistical calculations regarding the emission volumes of specific blocks or products, cross-regional transportation emission variations, and core emission stages. Traditional workflows rely on manual data filtering, writing database queries or analysis scripts, and drafting reports manually
. This process is highly time-consuming and imposes stringent technical requirements on operators.
These technical barriers are particularly evident among non-R&D business groups. Most accounting personnel possess solid domain knowledge but lack programming skills and the ability to perform complex interactive data analysis
| [12] | Hu, C., Dalal, D., & Zhou, X. (2025). A Dataset-Centric Survey of LLM-Agents for Data Science. Available from:
https://openreview.net/forum?id=W4hexmqgoN#discussion |
| [13] | Zhang, J., Zhang, H., Chakravarti, R., Hu, Y., Ng, P., Katsifodimos, A., Rangwala, H., Karypis, G., & Halevy, A. (2025). CoddLLM: Empowering large language models for data analytics. arXiv preprint arXiv: 2502.00329.
https://doi.org/10.48550/arXiv.2502.00329 |
[12, 13]
. Under the traditional paradigm, routine business queries require frequent switching among spreadsheet software, databases, scripting environments, and visualization tools, often necessitating the intervention of specialized technical staff. This limitation reduces data utilization efficiency and struggles to support high-frequency and flexible business decisions that require deep interactions
| [14] | Seow, M.-J., & Qian, L. (2024). Knowledge augmented intelligence using large language models for advanced data analytics. SPE Eastern Regional Meeting, SPE-221375-MS.
https://doi.org/10.2118/221375-MS |
[14]
. This issue becomes especially prominent in cross-analysis scenarios involving multiple blocks and product types.
The development of large language models provides a feasible pathway to alleviate the aforementioned challenges
| [15] | Brown, Tom B., Mann, Benjamin, Ryder, Nick, Subbiah, Melanie, Kaplan, Jared, Dhariwal, Prafulla, Neelakantan, Arvind, Shyam, Pranav, Sastry, Girish, Askell, Amanda, Agarwal, Sandhini, Herbert-Voss, Ariel, Krueger, Gretchen, Henighan, Tom, Child, Rewon, Ramesh, Aditya, Ziegler, Daniel M., Wu, Jeffrey, Winter, Clemens, Hesse, Christopher, Chen, Mark, Sigler, Eric, Litwin, Mateusz, Gray, Scott, Chess, Benjamin, Clark, Jack, Berner, Christopher, McCandlish, Sam, Radford, Alec, Sutskever, Ilya, & Amodei, Dario. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems, 33, 1877-1901.
https://doi.org/10.48550/arXiv.2005.14165 |
| [16] | OpenAI. (2023). GPT-4 technical report. arXiv preprint arXiv: 2303.08774. https://doi.org/10.48550/arXiv.2303.08774 |
[15, 16]
. Natural language interfaces for databases allow users to express query intentions using conversational language, lowering the access barrier to structured data
| [8] | Katsogiannis-Meimarakis, George, & Koutrika, Georgia. (2023). A survey on deep learning approaches for text-to-SQL. The VLDB Journal, 32(4), 905-936.
https://doi.org/10.1007/s00778-022-00776-8 |
| [9] | Hong, Zuyan, Yuan, Zheng, Zhang, Qiang, Chen, Hongyang, Dong, Junnan, Huang, Fei, & Huang, Xiao. (2024). Next-generation database interfaces: A survey of LLM-based text-to-SQL. arXiv preprint arXiv: 2406.08426.
https://doi.org/10.48550/arXiv.2406.08426 |
[8, 9]
. Agent reasoning and tool invocation frameworks based on large language models endow systems with the comprehensive ability to understand requirements, plan execution steps, call external tools, and observe environmental feedback
| [17] | Yao, Shunyu, Zhao, Jeffrey, Yu, Dian, Du, Nan, Shafran, Izhak, Narasimhan, Karthik, & Cao, Yuan. (2022). ReAct: Synergizing reasoning and acting in language models. arXiv preprint arXiv: 2210.03629. https://doi.org/10.48550/arXiv.2210.03629 |
| [18] | Chen, X., & Zeng, A. (2024). A survey on large language model based autonomous agents. In CCL 2024-23rd Chinese Natl Conf Comput Linguist (Vol. 2, No. 6, pp. 141-150).
https://doi.org/10.1007/s11704-024-40231-1 |
[17, 18]
. Compared to traditional question-answering systems, these agents generate text while autonomously executing database retrievals, running code, rendering charts, and compiling structured reports. This mechanism effectively transforms semantic understanding into practical data analysis workflows.
During the evolution of data intelligence, data processing systems transition from mechanized rule scheduling to intent-driven intelligent collaboration
| [19] | Dong, Q., Li, L., Dai, D., Zheng, C., Ma, J., Li, R.,... & Sui, Z. (2024, November). A survey on in-context learning. In Proceedings of the 2024 conference on empirical methods in natural language processing (pp. 1107-1128).
https://doi.org/10.18653/v1/2024.emnlp-main.64 |
| [20] | Debnath, T., Siddiky, M. N. A., Rahman, M. E., Das, P., Guha, A. K., Rahman, M. R., & Kabir, H. M. (2025). A comprehensive survey of prompt engineering techniques in large language models. TechRxiv. https://doi.org/10.36227/techrxiv.174140719.96375390/v2 |
[19, 20]
. Early enterprise systems primarily updated reports through scheduled scripts and data extraction tools, and later evolved into comprehensive data governance platforms, yet these systems still lacked the capacity to directly parse user intentions. The introduction of large language models transforms this paradigm, driving data systems to evolve from passive tools into intelligent analytical agents capable of interaction, planning, and execution
| [18] | Chen, X., & Zeng, A. (2024). A survey on large language model based autonomous agents. In CCL 2024-23rd Chinese Natl Conf Comput Linguist (Vol. 2, No. 6, pp. 141-150).
https://doi.org/10.1007/s11704-024-40231-1 |
[18]
. With the advancement of multi-agent collaboration technologies, data agents increasingly serve as the core medium connecting natural language interactions with complex data operations
| [21] | Wu, Q., Bansal, G., Zhang, J., Wu, Y., Li, B., Zhu, E.,... & Wang, C. (2024, August). Autogen: Enabling next-gen LLM applications via multi-agent conversations. In First conference on language modeling.
https://doi.org/10.48550/arXiv.2308.08155 |
| [22] | Tran, Khanh-Tung, Nguyen, Thai-Hoang, & Nguyen, Le-Minh. (2025). Multi-agent collaboration mechanisms: A survey of LLMs. arXiv preprint arXiv: 2501.06322.
https://doi.org/10.48550/arXiv.2501.06322 |
[21, 22]
.
Although existing research achieves progress in general database question-answering and automatic report generation, agent research targeting the carbon footprint analysis scenario in the petroleum industry remains insufficient
| [23] | Yehudai, A., Eden, L., Li, A., Uziel, G., Zhao, Y., Bar-Haim, R. & Shmueli-Scheuer, M. (2025). Survey on evaluation of llm-based agents. arXiv preprint arXiv: 2503.16416.
https://doi.org/10.48550/arXiv.2503.16416 |
[23]
. This scenario deeply integrates structured queries, domain knowledge logic, and multimodal result expression. General database question-answering models struggle to directly handle multi-source heterogeneous table environments, and traditional business intelligence systems cannot support natural language-driven dynamic interaction and automatic report generation. Carbon footprint analysis requires accurate data retrieval alongside the interpretation of emission drivers based on industry background to assist decision-making
| [14] | Seow, M.-J., & Qian, L. (2024). Knowledge augmented intelligence using large language models for advanced data analytics. SPE Eastern Regional Meeting, SPE-221375-MS.
https://doi.org/10.2118/221375-MS |
[14]
. Therefore, constructing a multi-agent system that integrates semantic understanding, task planning, logical querying, and visual report generation holds significant engineering application value.
To address these requirements, this paper proposes a multi-agent framework for oilfield carbon emission data analysis
. This framework utilizes heterogeneous carbon emission data from multiple blocks and product types as the foundation, providing underlying support for natural language analysis through automated data loading and structured reorganization
| [25] | Boda, V. V. R. (2026). Design and Implementation of a High-Availability Enterprise Data Integration System Using Automated ETL Pipelines. International Journal of AI, BigData, Computational and Management Studies, 222-231.
Available from: https://ijaibdcms.org/index.php/ijaibdcms/article/view/414 |
[25]
. The system integrates the task planning and tool execution mechanisms of large language models to construct an end-to-end data analysis pipeline encompassing semantic understanding, intent decomposition, code generation, and report output
| [13] | Zhang, J., Zhang, H., Chakravarti, R., Hu, Y., Ng, P., Katsifodimos, A., Rangwala, H., Karypis, G., & Halevy, A. (2025). CoddLLM: Empowering large language models for data analytics. arXiv preprint arXiv: 2502.00329.
https://doi.org/10.48550/arXiv.2502.00329 |
| [26] | Rawat, Manish, et al. (2025). Pre-Act: Multi-step planning and reasoning improves acting in LLM agents. arXiv preprint arXiv: 2505.09970. https://doi.org/10.48550/arXiv.2505.09970 |
[13, 26]
. Tailored for business personnel without programming backgrounds, the system automatically identifies analysis objectives based on natural language inputs, coordinates databases and visualization components, and completes complex tasks such as emission volume statistics, cross-block comparisons, trend plotting, and comprehensive report generation. By incorporating real-world oilfield carbon emission data scenarios, this paper validates the query efficiency, interaction convenience, and analysis report generation capabilities of the framework in multi-source heterogeneous data environments. This framework provides a highly scalable intelligent analysis solution for the low-carbon digital transformation of the petroleum industry.
2. Related Work
The realization of an intelligent carbon footprint analysis system for the petroleum industry requires a multidisciplinary integration of environmental accounting, natural language processing, and autonomous agent architectures. This chapter reviews the theoretical foundations and technical evolution relevant to our proposed framework. We first examine the current state of carbon footprint accounting within the energy sector, followed by an analysis of data-driven interaction paradigms such as Text-to-SQL. Finally, we discuss the development of large language model agents and retrieval-augmented generation techniques, which provide the essential logical reasoning and knowledge support for complex analytical tasks.
2.1. Carbon Footprint Analysis and Petroleum Industry Applications
Carbon footprint analysis is an effective method for measuring the greenhouse gas emission levels of products, processes, or organizations throughout their entire life cycle
| [3] | International Organization for Standardization. (2006). ISO 14040: 2006 Environmental management — Life cycle assessment — Principles and framework.
Available from: https://www.iso.org/standard/37456.html |
| [4] | International Organization for Standardization. (2006). ISO 14044: 2006 Environmental management — Life cycle assessment — Requirements and guidelines.
Avaulable from: https://www.iso.org/standard/38498.html |
[3, 4]
. This analysis constitutes the technical foundation for the green and low-carbon transition of the energy industry. With the advancement of dual carbon goals, carbon emission accounting evolves from single-stage statistics into a systematic evaluation framework encompassing raw material acquisition, production and processing, transportation and distribution, and final disposal. The business chain of the petroleum industry spans exploration, development, gathering and transportation, refining, and consumption. These operations present characteristics of long processes, multiple participants, complex emission sources, and highly dispersed regions. Therefore, systematic carbon footprint analysis serves as vital support for the industry to implement energy conservation, emission reduction, and management decision optimization.
Existing carbon footprint research primarily relies on life cycle assessment theory to evaluate environmental impacts by quantifying energy consumption, material input, transportation distance, and emission factors
| [5] | Jamaludin, N. F., Shuhaimi, N. A., Mohamed, O. Y., & Hadipornama, M. F. (2023). Quantification of Carbon Footprint in Petroleum Refinery Process. Chemical Engineering Transactions, 106, 97-102. https://doi.org/10.3303/CET23106017 |
| [6] | Zhao, Hujie, Zhao, Dongfeng, Song, Qingbin, & Wang, Yongqiang. (2023). Identifying the spatiotemporal carbon footprint of the petroleum refining industry and its mitigation potential in China. Energy, 284, 129240.
https://doi.org/10.1016/j.energy.2023.129240 |
| [7] | Chevron. (2023). Chevron supports a lifecycle approach to carbon accounting. Chevron Climate Change Resilience Report 2023. Available from:
https://www.chevron.com/-/media/chevron/sustainability/documents/2023CCRR-CarbonAccounting.pdf |
[5-7]
. This methodological system is relatively mature and finds widespread application in the manufacturing and transportation sectors. However, the traditional accounting paradigm faces multiple realistic challenges during practical application within the petroleum industry
| [8] | Katsogiannis-Meimarakis, George, & Koutrika, Georgia. (2023). A survey on deep learning approaches for text-to-SQL. The VLDB Journal, 32(4), 905-936.
https://doi.org/10.1007/s00778-022-00776-8 |
| [9] | Hong, Zuyan, Yuan, Zheng, Zhang, Qiang, Chen, Hongyang, Dong, Junnan, Huang, Fei, & Huang, Xiao. (2024). Next-generation database interfaces: A survey of LLM-based text-to-SQL. arXiv preprint arXiv: 2406.08426.
https://doi.org/10.48550/arXiv.2406.08426 |
[8, 9]
. The integration of multi-source heterogeneous data is highly difficult because data from different blocks, products, and operational stages is often scattered across various tables. These tables exhibit significant differences in statistical standards, naming conventions, and recording granularity. Accounting workflows that rely on manual collection and filtering incur high time costs and are prone to calculation deviations due to inconsistent standards. As management dimensions become more refined, static accounting methods struggle to support the demands for dynamic monitoring, cross-block comparison, and multi-round cross-analysis.
The carbon emission analysis scenario in the petroleum industry exhibits high complexity
| [14] | Seow, M.-J., & Qian, L. (2024). Knowledge augmented intelligence using large language models for advanced data analytics. SPE Eastern Regional Meeting, SPE-221375-MS.
https://doi.org/10.2118/221375-MS |
[14]
. The analysis targets often involve horizontal comparisons across multiple oilfields and product types. The business focus also extends from simple total volume statistics to the tracing of emission causes, such as the attribution of cross-regional transportation emission differences or the precise localization of core emission stages. Such requirements depend on underlying structured data queries, visual result presentation, and logical explanation. Traditional static reports and database tools lack natural language interaction mechanisms and task linkage capabilities, making it difficult to effectively serve business personnel without programming backgrounds.
Recent studies attempt to introduce digital systems and decision support tools into the carbon management process to improve automation levels. However, most existing platforms still rely on predefined query templates and fixed views. They fail to respond to the flexible follow-up questions, cross-table calculations, and automatic generation of analysis reports required in real business scenarios. Therefore, constructing an intelligent carbon footprint analysis method that combines interactive usability, analytical rigor, and automated result generation for the petroleum industry holds significant engineering research value.
2.2. Text-to-SQL
Natural language data analysis technology allows users to express data processing requirements through everyday language. Based on these inputs, the system automatically completes intent parsing, query generation, and result feedback. Text-to-SQL, as the core technology in this field, translates natural language into executable SQL statements and significantly lowers the access barrier to structured data
| [8] | Katsogiannis-Meimarakis, George, & Koutrika, Georgia. (2023). A survey on deep learning approaches for text-to-SQL. The VLDB Journal, 32(4), 905-936.
https://doi.org/10.1007/s00778-022-00776-8 |
| [9] | Hong, Zuyan, Yuan, Zheng, Zhang, Qiang, Chen, Hongyang, Dong, Junnan, Huang, Fei, & Huang, Xiao. (2024). Next-generation database interfaces: A survey of LLM-based text-to-SQL. arXiv preprint arXiv: 2406.08426.
https://doi.org/10.48550/arXiv.2406.08426 |
[8, 9]
.
Early Text-to-SQL solutions primarily relied on semantic parsing and rule matching
| [27] | Devlin, Jacob, Chang, Ming-Wei, Lee, Kenton, & Toutanova, Kristina. (2019). BERT: Pre-training of deep bidirectional transformers for language understanding. Proc. NAACL-HLT, 4171-4186. https://doi.org/10.18653/v1/N19-1423 |
[27]
. These methods demonstrated certain effectiveness in simple databases with fixed schemas but exhibited limited generalization capacity when handling complex nested queries or open-ended expressions. With the development of neural network architectures, encoder-decoder models gradually become the mainstream approach
| [28] | Vaswani, Ashish, Shazeer, Noam, Parmar, Niki, Uszkoreit, Jakob, Jones, Llion, Gomez, Aidan N., Kaiser, Łukasz, & Polosukhin, Illia. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30, 5998-6008.
https://doi.org/10.48550/arXiv.1706.03762 |
[28]
, effectively improving the mapping accuracy between natural language and database schemas. The introduction of pre-trained large language models further enhances the capability to process multi-table joins and long-distance semantic dependencies, propelling the implementation of this technology in practical industrial scenarios.
Text-to-SQL still presents limitations when addressing complex enterprise-level applications
| [17] | Yao, Shunyu, Zhao, Jeffrey, Yu, Dian, Du, Nan, Shafran, Izhak, Narasimhan, Karthik, & Cao, Yuan. (2022). ReAct: Synergizing reasoning and acting in language models. arXiv preprint arXiv: 2210.03629. https://doi.org/10.48550/arXiv.2210.03629 |
| [18] | Chen, X., & Zeng, A. (2024). A survey on large language model based autonomous agents. In CCL 2024-23rd Chinese Natl Conf Comput Linguist (Vol. 2, No. 6, pp. 141-150).
https://doi.org/10.1007/s11704-024-40231-1 |
[17, 18]
. Real business environments often consist of unnormalized heterogeneous tables, including multi-source spreadsheet files and historical reports. The ambiguity of table structures and field semantics in these environments is significantly higher than that in standard public datasets. Practical analysis tasks usually transcend single data retrieval operations and require the system to possess composite capabilities of statistical calculation, chart rendering, and logical summarization. These requirements exceed the boundary of single-step SQL generation. A critical aspect is that the actual data exploration process typically manifests as continuous follow-up questions. The single-round generation mechanism struggles to maintain context consistency in multi-round dynamic interactions. This limitation prompts related research to gradually evolve from single query generation to intelligent agent frameworks that encompass the complete data analysis workflow.
2.3. LLM-Based Agents for Complex Reasoning
2.3.1. From Chain-of-Thought to ReAct
Large language models significantly improve the reasoning accuracy of complex logic
| [28] | Vaswani, Ashish, Shazeer, Noam, Parmar, Niki, Uszkoreit, Jakob, Jones, Llion, Gomez, Aidan N., Kaiser, Łukasz, & Polosukhin, Illia. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30, 5998-6008.
https://doi.org/10.48550/arXiv.1706.03762 |
[28]
. Early Chain-of-Thought methods enhanced the stability of models in logical problem-solving by explicitly outputting intermediate reasoning processes
| [29] | Wei, Jason, Wang, Xuezhi, Schuurmans, Dale, Maeda, Maarten, Polozov, Oleksandr, Le, Quoc V., & Zhou, Denny. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35, 24824-24837. https://doi.org/10.48550/arXiv.2201.11903 |
[29]
. This mechanism is mainly confined to the static internal reasoning of the model and cannot actively interact with external systems or calculation engines. Another category of methods emphasizing action generation endows models with the ability to call external tools. Due to the lack of an intermediate reflection step, these methods are prone to strategy deviation in multi-step tasks and struggle with self-correction.
The ReAct framework proposes a mechanism that integrates reasoning and action
| [17] | Yao, Shunyu, Zhao, Jeffrey, Yu, Dian, Du, Nan, Shafran, Izhak, Narasimhan, Karthik, & Cao, Yuan. (2022). ReAct: Synergizing reasoning and acting in language models. arXiv preprint arXiv: 2210.03629. https://doi.org/10.48550/arXiv.2210.03629 |
[17]
. The agent completes complex task-solving through a cycle of thinking, acting, and observing. The model no longer relies solely on internal parameters for reasoning but dynamically adjusts subsequent strategies based on environmental feedback.
This process is formally expressed as follows: at time , the agent policy generates the current thought and action based on the user query q and the previous observation history :
Subsequently, the external tool environment executes the action and returns a new observation result :
By continuously appending
to the context trajectory, the model progressively approaches the final objective through an iteration of guiding actions with thoughts and correcting thoughts with feedback
. For data analysis tasks that require high-frequency invocations of database and plotting modules, this mechanism demonstrates excellent adaptability
| [12] | Hu, C., Dalal, D., & Zhou, X. (2025). A Dataset-Centric Survey of LLM-Agents for Data Science. Available from:
https://openreview.net/forum?id=W4hexmqgoN#discussion |
| [13] | Zhang, J., Zhang, H., Chakravarti, R., Hu, Y., Ng, P., Katsifodimos, A., Rangwala, H., Karypis, G., & Halevy, A. (2025). CoddLLM: Empowering large language models for data analytics. arXiv preprint arXiv: 2502.00329.
https://doi.org/10.48550/arXiv.2502.00329 |
[12, 13]
.
2.3.2. Agent Framework for Data Analysis Tasks
The agent paradigm oriented towards data tasks is gradually maturing
| [18] | Chen, X., & Zeng, A. (2024). A survey on large language model based autonomous agents. In CCL 2024-23rd Chinese Natl Conf Comput Linguist (Vol. 2, No. 6, pp. 141-150).
https://doi.org/10.1007/s11704-024-40231-1 |
[18]
. It coordinates semantic understanding, data querying, result calculation, and visual reporting, which integrates fragmented analysis steps into a unified workflow. At the system architecture level, data agents are primarily divided into three modes
| [21] | Wu, Q., Bansal, G., Zhang, J., Wu, Y., Li, B., Zhu, E.,... & Wang, C. (2024, August). Autogen: Enabling next-gen LLM applications via multi-agent conversations. In First conference on language modeling.
https://doi.org/10.48550/arXiv.2308.08155 |
| [22] | Tran, Khanh-Tung, Nguyen, Thai-Hoang, & Nguyen, Le-Minh. (2025). Multi-agent collaboration mechanisms: A survey of LLMs. arXiv preprint arXiv: 2501.06322.
https://doi.org/10.48550/arXiv.2501.06322 |
[21, 22]
, which are single-agent direct execution, multi-agent collaboration, and planning-execution separation. The single-agent architecture is simple but prone to losing context in long processes. Multi-agent collaboration improves the processing upper limit through role division, but the system coordination overhead is large. The planning-execution separation mode achieves a favorable balance between logical controllability and system complexity by decoupling task breakdown from specific tool invocation
.
In carbon emission data analysis, the core advantage of the agent lies in scheduling the underlying toolchain centered on user intent and maintaining capacity for cross-round interaction and context maintenance. The system continues to respond to logical follow-up questions from users based on initial queries. This provides analysis flexibility that far exceeds traditional fixed template reports.
2.4. Retrieval-Augmented Generation
2.4.1. Basic Mechanism of RAG
Retrieval-Augmented Generation aims to fuse external knowledge base retrieval with model generation capabilities
| [30] | Lewis, Patrick, Perez, Ethan, Piktus, Aleksandra, Petroni, Fabio, Karpukhin, Vladimir, Goyal, Naman, Küttler, Heinrich, Lewis, Mike, Yih, Wen-tau, Rocktäschel, Tim, Riedel, Sebastian, & Kiela, Douwe. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems, 33, 9459-9474.
https://doi.org/10.48550/arXiv.2005.11401 |
[30]
. Before generating a response, the system prioritizes extracting document fragments relevant to the user query as supplementary context. This mechanism effectively mitigates defects such as the lack of domain knowledge and factual hallucination in models
| [31] | Gao, Yunfan, Xiong, Yun, Gao, Xinyu, Jia, Kangning, Pan, Jinliu, Bi, Yuxi, Dai, Yi, Sun, Jianyong, & Wang, Haofen. (2023). Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv: 2312.10997.
https://doi.org/10.48550/arXiv.2312.10997 |
[31]
.
Formally, assuming the user query is q, the knowledge base is , and the embedding function and similarity metric are and respectively. The retrieval stage extracts the top k most relevant document fragments:
The generation model then combines the query and the retrieval results to output the final answer :
2.4.2. Schema RAG and Document RAG for Structured Data Analysis
Conventional plain text retrieval struggles to support high-precision structured data queries
| [30] | Lewis, Patrick, Perez, Ethan, Piktus, Aleksandra, Petroni, Fabio, Karpukhin, Vladimir, Goyal, Naman, Küttler, Heinrich, Lewis, Mike, Yih, Wen-tau, Rocktäschel, Tim, Riedel, Sebastian, & Kiela, Douwe. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems, 33, 9459-9474.
https://doi.org/10.48550/arXiv.2005.11401 |
[30]
. Data analysis depends on business knowledge and database schemas, including table structures, field types, sample data, and relational links. The absence of such structural constraints easily leads to table name misuse or aggregation logic errors during SQL generation. Schema RAG provides the model with precise structured context before executing the query by transforming database schema information into retrievable units.
In the vertical domain of petroleum carbon emissions, the reasonable interpretation of data relies on industry standards, emission factors, and accounting norms. Document RAG focuses on introducing these unstructured domain files
| [30] | Lewis, Patrick, Perez, Ethan, Piktus, Aleksandra, Petroni, Fabio, Karpukhin, Vladimir, Goyal, Naman, Küttler, Heinrich, Lewis, Mike, Yih, Wen-tau, Rocktäschel, Tim, Riedel, Sebastian, & Kiela, Douwe. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems, 33, 9459-9474.
https://doi.org/10.48550/arXiv.2005.11401 |
| [31] | Gao, Yunfan, Xiong, Yun, Gao, Xinyu, Jia, Kangning, Pan, Jinliu, Bi, Yuxi, Dai, Yi, Sun, Jianyong, & Wang, Haofen. (2023). Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv: 2312.10997.
https://doi.org/10.48550/arXiv.2312.10997 |
[30, 31]
. Schema RAG solves the technical problem of accurate querying, while Document RAG provides the business background for reasonable interpretation. The combination of both constructs a complete knowledge enhancement chain for precise data analysis and professional report writing in complex business scenarios.
2.5. Positioning of This Work
Existing research establishes a foundation in carbon footprint theory, Text-to-SQL, and agent frameworks, but adaptability bottlenecks remain regarding the deep analysis of multi-source heterogeneous carbon emission data in the petroleum industry. Traditional methods rely on manual intervention. Text-to-SQL struggles to cover the complete analysis report generation pipeline, and general agents lack deep integration with the specific data structures and accounting logic of the vertical domain.
This paper focuses on the natural language-driven data analysis closed loop and proposes an agent framework tailored for oilfield carbon emission scenarios. This framework integrates heterogeneous data loading, structure understanding, task planning, tool invocation, chart rendering, and text report writing into a unified interactive process. This paper introduces a planning-execution separation architecture and a dual retrieval-augmented generation mechanism combining Schema RAG and Document RAG. While lowering the usage barrier for non-technical personnel, this design improves the accuracy of cross-table queries and the professionalism of analytical conclusions, which provides a highly feasible engineering implementation path for the intelligent analysis of petroleum industry data.
3. System Design and Methods
The intelligent analysis of oilfield carbon emission data necessitates a cohesive integration of heterogeneous data processing, semantic intent parsing, and automated task execution. This chapter details a natural language-driven agent framework specifically tailored for the petroleum industry. By constructing a multi-level architecture that encompasses a data layer, a retrieval augmentation layer, a planning-and-execution layer, and a result generation layer, the system achieves the effective integration and intelligent utilization of multi-source Excel data. Our design leverages dual retrieval-augmented generation mechanisms to compensate for the limitations of large language models in structural perception and domain knowledge, while the Planner-Executor workflow ensures the closed-loop processing of complex analytical tasks. The following sections describe the specific implementation of each module and the underlying methodological foundations.
3.1. Overall System Architecture
This paper designs and implements a natural language-driven agent analysis framework tailored for oilfield carbon emission data analysis. Based on heterogeneous carbon emission data across multiple blocks and products, the framework integrates large language models, retrieval-augmented generation (RAG), and tool invocation mechanisms
| [24] | Chase, Harrison. (2022). LangChain: Building applications with LLMs through composability. GitHub repository. Available from: https://github.com/langchain-ai/langchain |
| [30] | Lewis, Patrick, Perez, Ethan, Piktus, Aleksandra, Petroni, Fabio, Karpukhin, Vladimir, Goyal, Naman, Küttler, Heinrich, Lewis, Mike, Yih, Wen-tau, Rocktäschel, Tim, Riedel, Sebastian, & Kiela, Douwe. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems, 33, 9459-9474.
https://doi.org/10.48550/arXiv.2005.11401 |
[24, 30]
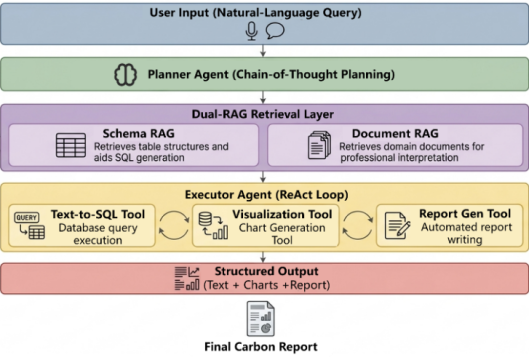
. It aims to transform natural language instructions from users into structured analysis workflows and ultimately deliver query results, visual charts, and analysis reports. As shown in
Figure 1, the architecture consists of a data layer, a retrieval augmentation layer, a task planning and execution layer, and a result generation layer
| [18] | Chen, X., & Zeng, A. (2024). A survey on large language model based autonomous agents. In CCL 2024-23rd Chinese Natl Conf Comput Linguist (Vol. 2, No. 6, pp. 141-150).
https://doi.org/10.1007/s11704-024-40231-1 |
[18]
, forming a complete processing chain from requirement input to result delivery
| [21] | Wu, Q., Bansal, G., Zhang, J., Wu, Y., Li, B., Zhu, E.,... & Wang, C. (2024, August). Autogen: Enabling next-gen LLM applications via multi-agent conversations. In First conference on language modeling.
https://doi.org/10.48550/arXiv.2308.08155 |
| [22] | Tran, Khanh-Tung, Nguyen, Thai-Hoang, & Nguyen, Le-Minh. (2025). Multi-agent collaboration mechanisms: A survey of LLMs. arXiv preprint arXiv: 2501.06322.
https://doi.org/10.48550/arXiv.2501.06322 |
[21, 22]
.
The system workflow operates as follows: users input The workflow is as follows. Users first submit analysis requirements in natural language, such as oilfield-level emission queries, cross-block comparison requests, or report-generation tasks. After receiving the request, the system performs context grounding through dual retrieval, combining database schema information with domain knowledge documents. The Planner Agent then identifies user intent and decomposes the request into executable subtasks, while the Executor Agent invokes corresponding tools for database querying, data processing, chart generation, and report writing. Finally, the system returns structured outputs, including textual responses, visual graphics, and report files. Through this unified architecture, fragmented operations that traditionally require switching among spreadsheets, database terminals, and scripting environments are integrated into a coherent analysis pipeline.
Figure 1. Overall architecture of the conversation-driven oilfield carbon-emission analytics framework. Overall architecture of the conversation-driven oilfield carbon-emission analytics framework.
3.2. Data Layer Design
The foundational data of the system originates from decentralized Excel files
| [25] | Boda, V. V. R. (2026). Design and Implementation of a High-Availability Enterprise Data Integration System Using Automated ETL Pipelines. International Journal of AI, BigData, Computational and Management Studies, 222-231.
Available from: https://ijaibdcms.org/index.php/ijaibdcms/article/view/414 |
[25]
. Since the data is generated across different business stages, issues such as inconsistent table structures, redundant field naming, and variations in recording granularity exist. To address this, this paper designs an automated access mechanism that traverses designated directories during the system initialization phase to extract metadata, including oilfield names, product types, and source attributes. The system normalizes raw data into two core types of tables: transportation manifests and emission manifests
. Transportation manifests encompass dimensions such as raw material transport modes, loads, mileage, and emission factors, while emission manifests record activity data and emission details. Through field alignment and cleaning, heterogeneous data is converted into standardized structured data tables.
For the storage scheme, this paper employs an SQLite in-memory database to construct the analysis environment
. SQLite offers characteristics of being lightweight, easy to deploy, and requiring no independent service, which supports prototype verification effectively. Loading Excel data into the in-memory database improves real-time query efficiency and provides a stable structured interface for natural language-driven SQL generation. Compared to directly reading raw files, this approach significantly reduces IO overhead. Furthermore, the system temporarily stores query results in intermediate data objects for reuse by statistical analysis, plotting, and reporting modules, effectively avoiding redundant calculations and enhancing analytical linkage in multi-round interaction scenarios.
3.3. Dual-RAG Mechanism: Integrating Schema and Domain Knowledge
To strengthen the ability of the model to understand and interpret complex business logic, this paper constructs a dual retrieval augmentation mechanism, including Schema RAG and Document RAG
| [30] | Lewis, Patrick, Perez, Ethan, Piktus, Aleksandra, Petroni, Fabio, Karpukhin, Vladimir, Goyal, Naman, Küttler, Heinrich, Lewis, Mike, Yih, Wen-tau, Rocktäschel, Tim, Riedel, Sebastian, & Kiela, Douwe. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems, 33, 9459-9474.
https://doi.org/10.48550/arXiv.2005.11401 |
| [31] | Gao, Yunfan, Xiong, Yun, Gao, Xinyu, Jia, Kangning, Pan, Jinliu, Bi, Yuxi, Dai, Yi, Sun, Jianyong, & Wang, Haofen. (2023). Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv: 2312.10997.
https://doi.org/10.48550/arXiv.2312.10997 |
[30, 31]
, providing structured information support and domain knowledge assurance respectively.
Schema RAG aims to improve the awareness of the model regarding the database environment. Oilfield carbon emission analysis frequently involves multi-table joins and multi-dimensional statistics. Without an accurate grasp of the underlying schema, the model is prone to field misuse or logical deviations during SQL generation. This paper organizes table names, column names, field semantics, data types, and sample records into a structured knowledge base. When parsing user queries, the system prioritizes retrieving relevant database schema information and injecting it into the prompt to enhance the understanding of the data structure by the model.
Document RAG focuses on providing industry background knowledge. Carbon footprint accounting involves unstructured information such as emission factor selection, accounting boundary definition, and policy standards. By constructing a domain document library and establishing vector indices, the system can extract relevant accounting guidelines or terminology explanations in real time while performing analysis tasks. This mechanism ensures that the system not only completes numerical retrieval but also interprets results reasonably based on business backgrounds, achieving an organic integration of querying and analysis.
3.4. Planner-Executor: Coordinated Task Decomposition and Execution
Considering the multi-step and composite nature of analysis tasks, this paper adopts the Planner-Executor architecture to organize the workflow
| [17] | Yao, Shunyu, Zhao, Jeffrey, Yu, Dian, Du, Nan, Shafran, Izhak, Narasimhan, Karthik, & Cao, Yuan. (2022). ReAct: Synergizing reasoning and acting in language models. arXiv preprint arXiv: 2210.03629. https://doi.org/10.48550/arXiv.2210.03629 |
| [26] | Rawat, Manish, et al. (2025). Pre-Act: Multi-step planning and reasoning improves acting in LLM agents. arXiv preprint arXiv: 2505.09970. https://doi.org/10.48550/arXiv.2505.09970 |
[17, 26]
, ensuring the controllability and stability of complex task execution
| [18] | Chen, X., & Zeng, A. (2024). A survey on large language model based autonomous agents. In CCL 2024-23rd Chinese Natl Conf Comput Linguist (Vol. 2, No. 6, pp. 141-150).
https://doi.org/10.1007/s11704-024-40231-1 |
[18]
.
The Planner module is responsible for high-level intent parsing and task decomposition
| [26] | Rawat, Manish, et al. (2025). Pre-Act: Multi-step planning and reasoning improves acting in LLM agents. arXiv preprint arXiv: 2505.09970. https://doi.org/10.48550/arXiv.2505.09970 |
| [29] | Wei, Jason, Wang, Xuezhi, Schuurmans, Dale, Maeda, Maarten, Polozov, Oleksandr, Le, Quoc V., & Zhou, Denny. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35, 24824-24837. https://doi.org/10.48550/arXiv.2201.11903 |
[26, 29]
. After receiving a natural language request, this module identifies task objectives, involved objects, and required operations based on the retrieved context to generate a logically clear execution plan. Simple tasks are typically decomposed into schema checks, data queries, and conclusion summarization, while complex tasks extend further to multi-dimensional comparisons, chart plotting, and report generation. The explicit planning process effectively reduces the randomness associated with direct answer generation
| [20] | Debnath, T., Siddiky, M. N. A., Rahman, M. E., Das, P., Guha, A. K., Rahman, M. R., & Kabir, H. M. (2025). A comprehensive survey of prompt engineering techniques in large language models. TechRxiv. https://doi.org/10.36227/techrxiv.174140719.96375390/v2 |
[20]
.
The Executor module executes specific subtasks. This module follows a mechanism of alternating reasoning and action, determining the type of tool to invoke, such as SQL queries, document retrieval, or plotting tools, based on the execution plan and current state. Observation results from tool feedback are reintroduced into the context to guide the model in determining the next action. This three-stage processing flow of retrieval, planning, and execution retains the flexibility to handle complex business logic while controlling system complexity.
3.5. Tool Invocation and Result Generation Mechanism
This paper encapsulates core analysis functions into three types of invokable tools
| [12] | Hu, C., Dalal, D., & Zhou, X. (2025). A Dataset-Centric Survey of LLM-Agents for Data Science. Available from:
https://openreview.net/forum?id=W4hexmqgoN#discussion |
| [13] | Zhang, J., Zhang, H., Chakravarti, R., Hu, Y., Ng, P., Katsifodimos, A., Rangwala, H., Karypis, G., & Halevy, A. (2025). CoddLLM: Empowering large language models for data analytics. arXiv preprint arXiv: 2502.00329.
https://doi.org/10.48550/arXiv.2502.00329 |
[12, 13]
: Data access tools are responsible for database schema retrieval, SQL execution, and document searching, forming the data foundation of analysis tasks. Data processing and visualization tools perform statistical calculations and variable transformations based on query results and automatically render visual components such as bar charts and line charts. Since the system uses an intermediate variable storage mechanism, plotting tools can directly call processed data, ensuring the continuity of the task chain. Report generation tools integrate analysis conclusions, statistical data, and chart references into Word documents to meet reporting and archiving requirements in petroleum industry carbon management.
Regarding result delivery, the system emphasizes multimodal output. In addition to returning raw data, the system automatically generates natural language summaries to interpret anomalies or differences in key indicators. For visualization requirements, the system embeds charts directly into the interaction interface. Furthermore, by maintaining dialogue states, the system supports continuous follow-up questions based on current analysis results, thereby achieving deep interactive data exploration
.
system provides feedback to users in the form of structured data, visual graphics, and natural language summaries. This architecture integrates fragmented processes that traditionally require switching among spreadsheet software, database terminals, and scripting environments into a unified framework, achieving integrated processing for oilfield carbon emission analysis tasks.
3.6. Summary
This chapter details the design of the agent system for oilfield carbon emission analysis. By constructing a multi-level architecture encompassing the data layer, retrieval augmentation layer, planning and execution layer, and result generation layer, the system achieves effective integration and intelligent utilization of heterogeneous Excel data. The dual retrieval augmentation mechanism compensates for the shortcomings of the model in structural perception and domain knowledge, while the Planner-Executor workflow ensures closed-loop processing of complex tasks. These designs provide the methodological foundation for subsequent experimental verification and application case analysis.
4. Experiments
4.1. Experimental Setup and Datasets
To validate the effectiveness of the proposed agent framework for oilfield carbon emission data analysis, we implement the system in real-world business scenarios and conduct experiments on tasks including natural language querying, statistical analysis, visualization generation, report output, and multi-turn follow-up questions. The experimental environment is built on the Windows platform. The system utilizes Python as the primary development language, LangChain and LangGraph as agent orchestration frameworks, SQLite as the unified data storage and querying environment, FAISS as the vector retrieval engine, DeepSeek as the core large language model, and bge-small-zh-v1.5 as the text embedding model. The system supports automatic loading of carbon emission data from multiple Excel files, completing table structure unification, meta-information supplementation, and database import.
Regarding the dataset, the experimental data originates from carbon emission inventory files of multiple oilfields, covering various oilfields, product types, and emission record formats. Upon initialization, the system automatically identifies the file structures and performs unified organization, ultimately constructing a transportation inventory data table. This table primarily includes fields such as raw and auxiliary material weight, transportation mode, distance, emission factor, and emission volume. After data loading and cleaning, the experimental dataset covers 13 oilfields with 2817 transportation inventory records, which supports carbon emission analysis tasks across different oilfields, product types, and scenarios.
To enhance system performance in complex queries and domain interpretations, we construct two types of retrieval knowledge bases. The first is a schema knowledge base, a structured retrieval base consisting of database table structures, field information, sample field values, and example records, which assists the model in understanding database patterns and improves SQL generation accuracy. The second is a domain document knowledge base, an unstructured knowledge base formed by segmenting carbon footprint explanatory documents, standard knowledge, or business materials, which supports the model in interpreting query results in a manner more aligned with the domain context. In the experiments, if the domain document base is empty, the system only activates schema RAG; if domain materials exist, it activates both schema RAG and document RAG.
4.2. Experimental Tasks and Evaluation Metrics
To comprehensively evaluate the capability of the proposed system in oilfield carbon emission analysis scenarios, we design five task categories that correspond to common business requirements: basic querying, statistical analysis, visualization generation, report generation, and multi-turn follow-up. Specifically, the evaluation set contains 30 test tasks, including 8 basic querying tasks, 8 statistical analysis tasks, 6 visualization generation tasks, 4 report generation tasks, and 4 multi-turn follow-up tasks. All test queries are derived from typical user requirements in oilfield operations.
The basic querying category tests system understanding of database structure and core information, such as identifying the number of oilfields in the database, listing product types for a specific oilfield, and retrieving key fields of a target table. The statistical analysis category focuses on aggregation and comparative reasoning, such as computing total emissions by oilfield, comparing transportation-stage emissions across oilfields, and analyzing the emission distribution of a specific product type across multiple oilfields. The visualization generation category evaluates whether the system can automatically produce compliant charts from query results, including bar charts, line charts, and pie charts. The report generation category evaluates whether the system can integrate textual analysis, statistical outputs, and charts into deliverable Word reports. The multi-turn follow-up category evaluates contextual continuity in dialogue, specifically whether the system can answer subsequent questions based on previous analytical results.
To ensure comparability, we pre-construct a test set for each category and prepare manually verified reference answers for basic querying and statistical analysis tasks. For visualization and report tasks, we evaluate both completion status and requirement compliance. For multi-turn tasks, we further adopt manual scoring from three perspectives: contextual consistency, answer completeness, and analytical rationality.
To quantitatively evaluate system performance, we use five metrics: Task Completion Rate (TCR), SQL Semantic Consistency Rate (SSR), Visualization Success Rate (VSR), Report Quality Score (RQS), and Multi-turn Consistency Score (MCS). TCR measures whether a task is successfully completed. SSR evaluates whether generated SQL is not only executable but also semantically aligned with the user query, including correct field selection, filtering conditions, grouping, and aggregation logic. VSR measures whether generated visualizations satisfy task requirements. RQS measures report quality (including textual content and chart references) using manual scoring on a 1-5 scale. MCS measures contextual coherence across follow-up interactions, also using manual scoring on a 1-5 scale. To reduce randomness, all system variants are evaluated under the same dataset, model setting, and runtime environment, and reported results are aggregated across runs.
4.3. Empirical Results and Comparative Analysis
To validate the contribution of each module, we compare four system configurations:
1) Baseline (LLM + Tools),
2) +Schema RAG,
3) +Planner-Executor, and
4) Full (Schema RAG + Document RAG + Planner-Executor).
We construct a baseline system based on a strong large language model (DeepSeek) with direct tool invocation capabilities, but without explicit planning (i.e., Planner-Executor) or retrieval augmentation (RAG). In this setting, the model generates SQL queries and invokes tools in a single-step or implicitly reasoned manner, without structured task decomposition or external knowledge grounding. This baseline reflects a commonly adopted paradigm in practical LLM-based data analysis systems, where models rely primarily on internal reasoning and direct tool usage. All settings are evaluated under the same dataset, model, and runtime environment. The overall results are shown in
Table 1. Results are reported on the 30-task benchmark defined in Section 4.2
Table 1. Overall performance comparison across system configurations.
Method | TCR (%) | SSR (%) | VSR (%) | RQS (1-5) | MCS (1-5) |
Baseline | 80.0 | 87.5 | 66.7 | 3.2 | 3.3 |
+Schema RAG | 83.3 | 93.8 | 83.3 | 3.6 | 3.6 |
+ Planner-Executor | 90.0 | 95.8 | 83.3 | 3.9 | 4.0 |
Full (Schema + Doc RAG + Planner) | 93.3 | 95.8 | 100.0 | 4.6 | 4.5 |
As shown in Table1, performance improves consistently as modules are added. The Baseline already achieves acceptable usability (TCR=80.0%). After introducing Schema RAG, SSR increases from 87.5% to 93.8% and VSR from 66.7% to 83.3%, indicating that schema-aware retrieval improves field grounding and query robustness. Adding Planner-Executor further raises TCR to 90.0% and MCS from 3.3 to 4.0, showing better stability in multi-step execution and follow-up interactions. The Full setting further improves visualization and report quality (VSR=100.0%, RQS=4.6), suggesting that Document RAG provides clear benefits for explanation and report composition.
To provide a finer-grained view, we also report performance by task type in
Table 2.
Table 2. Performance by task type across system configurations.
Method | Basic (%) | Stats (%) | Viz (%) | RQS (1-5) | MCS (1-5) |
Baseline | 87.5 | 75.0 | 66.7 | 3.2 | 3.3 |
+ Schema RAG | 100.0 | 87.5 | 83.3 | 3.6 | 3.6 |
+ Planner-Executor | 100.0 | 87.5 | 83.3 | 3.9 | 4.0 |
Full (Schema + Doc RAG + Planner) | 100.0 | 87.5 | 100.0 | 4.6 | 4.5 |
From
Table 2, four observations can be made. First, basic query performance reaches 100.0% once Schema RAG is enabled, confirming the value of structural grounding for straightforward data access. Second, the largest gain in statistical tasks appears from Baseline to +Schema RAG (75.0%→87.5%), after which performance plateaus, suggesting that schema understanding and SQL generation are the main bottlenecks for this task type. Third, visualization and report quality reach their best values under the Full setting (viz=100.0%, RQS=4.6), indicating that Document RAG improves interpretability and report usability. Fourth, multi-turn quality (MCS) rises from 3.3 to 4.5, showing that Planner-Executor is critical for contextual continuity and multi-step coordination. Overall, the results demonstrate complementary gains from Schema RAG, Planner-Executor, and Document RAG for carbon-emission analytics.
4.4. Case Demonstration
This subsection presents three representative examples from real business scenarios to demonstrate the system’s capabilities in query answering, analytical comparison, and automated report generation.
All data shown in this subsection are anonymized.
Case 1 focuses on cross-oilfield emission comparison.
User Query: What is the carbon-emission difference between Oilfield A and Oilfield P?
System Output: The system returns the emission difference between Oilfield A and Oilfield P, including the absolute gap and the relative percentage difference.
As shown in
Figure 2, the system can complete cross-entity comparison through a single natural-language query.
Figure 2. Cross-oilfield carbon-emission difference analysis between Oilfield A and Oilfield P.
Case 2 focuses on key contributor analysis and visualization.
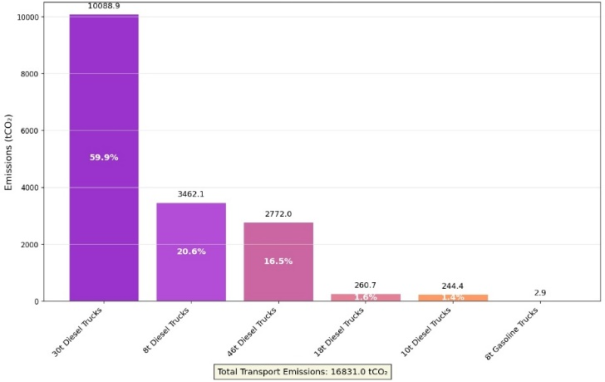
User Query: Analyze the D Oilfield and generate charts.
System Output: The system examines the transport list and emission list tables of Oilfield D, conducts multi-dimensional analysis (including emissions by process, product type, top materials, transportation mode and vehicle type), and automatically generates a series of corresponding visual charts as well as a comprehensive breakdown chart.
As shown in
Figure 3, the system supports integrated analytical reasoning and chart generation.
Figure 3. Oilfield D: Transport Emissions by Vehicle Type.
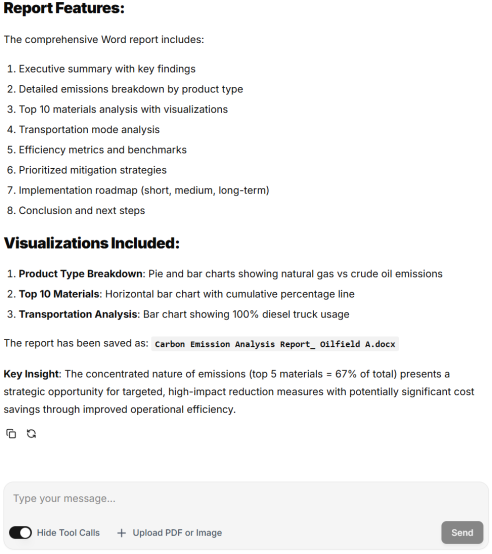
Case 3 focuses on automated report generation.
User Query: Generate a carbon-emission analysis report for Oilfield A.
System Output: The system automatically generates a structured carbon-emission analysis report for Oilfield A, including key emission contributors and concise findings.
As shown in
Figure 4, the system can produce report-ready outputs directly from natural-language instructions.
Figure 4. Automated carbon-emission report generation output for Oilfield A, including report components and visualization summary.
These examples verify the workflow from natural-language input to structured output.
The three cases are selected for demonstration only; in practical deployment, the agent can support many additional tasks, including full-dataset analysis across all oilfields and products, multi-entity comparison, trend analysis, and batch report generation. It should be noted that all data presented in the aforementioned examples is simulated and used solely for demonstration.
5. Conclusions
This paper proposes a natural language-driven multi-agent framework to address the challenges of multi-source heterogeneous data, complex operational workflows, and high technical barriers in carbon footprint analysis within the petroleum industry. By integrating large language models, a dual retrieval-augmented generation mechanism with Schema RAG and Document RAG, and a Planner-Executor workflow, the proposed system unifies structured data querying, multi-dimensional statistical analysis, visual chart rendering, and professional report writing into an end-to-end interactive loop. Experimental evaluations validate the individual contributions of the core modules. Specifically, Schema RAG significantly enhances structural perception and cross-table query accuracy within multi-table environments; the Planner-Executor architecture guarantees robust execution stability across multi-step tasks and contextual continuity in continuous dialogue scenarios; and Document RAG provides analytical outputs with domain-specific interpretability and high-quality report generation capabilities. Consequently, this framework not only lowers the technical threshold for business personnel without programming expertise to conduct complex data explorations but also improves the efficiency of data asset utilization. It offers a highly scalable, flexible, and efficient engineering solution to support dynamic carbon emission monitoring and the broader low-carbon digital transformation of the petroleum industry.
Abbreviations
LLM | Large Language Model |
RAG | Retrieval-Augmented Generation |
TCR | Task Completion Rate |
SSR | SQL Semantic Consistency Rate |
VSR | Visualization Success Rate |
RQS | Report Quality Score |
MCS | Multi-turn Consistency Score |
SQL | Structured Query Language |
Author Contributions
Qihang Liu: Data curation, Methodology, Software, Writing – original draft
Wenjia Xu: Conceptualization, Resources, Validation, Writing – review & editing
Funding
This work was supported by the Basic Scientific Research and Strategic Reserve Technology Research Fund of China National Petroleum Corporation (Grant No. 2023DQ03-A3).
Conflicts of Interest
The authors declare no conflicts of interest.
References
| [1] |
IPCC. (2024). Task Force on National Greenhouse Gas Inventories. Intergovernmental Panel on Climate Change. Available from:
https://www.ipcc.ch/working-group/tfi/
|
| [2] |
World Resources Institute, & World Business Council for Sustainable Development. (2004). The Greenhouse Gas Protocol: A corporate accounting and reporting standard (Revised ed.). Available from:
https://ghgprotocol.org/corporate-standard
|
| [3] |
International Organization for Standardization. (2006). ISO 14040: 2006 Environmental management — Life cycle assessment — Principles and framework.
Available from:
https://www.iso.org/standard/37456.html
|
| [4] |
International Organization for Standardization. (2006). ISO 14044: 2006 Environmental management — Life cycle assessment — Requirements and guidelines.
Avaulable from:
https://www.iso.org/standard/38498.html
|
| [5] |
Jamaludin, N. F., Shuhaimi, N. A., Mohamed, O. Y., & Hadipornama, M. F. (2023). Quantification of Carbon Footprint in Petroleum Refinery Process. Chemical Engineering Transactions, 106, 97-102.
https://doi.org/10.3303/CET23106017
|
| [6] |
Zhao, Hujie, Zhao, Dongfeng, Song, Qingbin, & Wang, Yongqiang. (2023). Identifying the spatiotemporal carbon footprint of the petroleum refining industry and its mitigation potential in China. Energy, 284, 129240.
https://doi.org/10.1016/j.energy.2023.129240
|
| [7] |
Chevron. (2023). Chevron supports a lifecycle approach to carbon accounting. Chevron Climate Change Resilience Report 2023. Available from:
https://www.chevron.com/-/media/chevron/sustainability/documents/2023CCRR-CarbonAccounting.pdf
|
| [8] |
Katsogiannis-Meimarakis, George, & Koutrika, Georgia. (2023). A survey on deep learning approaches for text-to-SQL. The VLDB Journal, 32(4), 905-936.
https://doi.org/10.1007/s00778-022-00776-8
|
| [9] |
Hong, Zuyan, Yuan, Zheng, Zhang, Qiang, Chen, Hongyang, Dong, Junnan, Huang, Fei, & Huang, Xiao. (2024). Next-generation database interfaces: A survey of LLM-based text-to-SQL. arXiv preprint arXiv: 2406.08426.
https://doi.org/10.48550/arXiv.2406.08426
|
| [10] |
Alation. (2025). Natural language interfaces: A guide to benefits & use cases. Available from:
https://www.alation.com/blog/natural-language-data-interfaces-guide/
|
| [11] |
Sigma Computing. (2025). How augmented analytics and NLP elevate business intelligence (BI). Available from:
https://www.sigmacomputing.com/blog/augmented-analytics-nlp-bi
|
| [12] |
Hu, C., Dalal, D., & Zhou, X. (2025). A Dataset-Centric Survey of LLM-Agents for Data Science. Available from:
https://openreview.net/forum?id=W4hexmqgoN#discussion
|
| [13] |
Zhang, J., Zhang, H., Chakravarti, R., Hu, Y., Ng, P., Katsifodimos, A., Rangwala, H., Karypis, G., & Halevy, A. (2025). CoddLLM: Empowering large language models for data analytics. arXiv preprint arXiv: 2502.00329.
https://doi.org/10.48550/arXiv.2502.00329
|
| [14] |
Seow, M.-J., & Qian, L. (2024). Knowledge augmented intelligence using large language models for advanced data analytics. SPE Eastern Regional Meeting, SPE-221375-MS.
https://doi.org/10.2118/221375-MS
|
| [15] |
Brown, Tom B., Mann, Benjamin, Ryder, Nick, Subbiah, Melanie, Kaplan, Jared, Dhariwal, Prafulla, Neelakantan, Arvind, Shyam, Pranav, Sastry, Girish, Askell, Amanda, Agarwal, Sandhini, Herbert-Voss, Ariel, Krueger, Gretchen, Henighan, Tom, Child, Rewon, Ramesh, Aditya, Ziegler, Daniel M., Wu, Jeffrey, Winter, Clemens, Hesse, Christopher, Chen, Mark, Sigler, Eric, Litwin, Mateusz, Gray, Scott, Chess, Benjamin, Clark, Jack, Berner, Christopher, McCandlish, Sam, Radford, Alec, Sutskever, Ilya, & Amodei, Dario. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems, 33, 1877-1901.
https://doi.org/10.48550/arXiv.2005.14165
|
| [16] |
OpenAI. (2023). GPT-4 technical report. arXiv preprint arXiv: 2303.08774.
https://doi.org/10.48550/arXiv.2303.08774
|
| [17] |
Yao, Shunyu, Zhao, Jeffrey, Yu, Dian, Du, Nan, Shafran, Izhak, Narasimhan, Karthik, & Cao, Yuan. (2022). ReAct: Synergizing reasoning and acting in language models. arXiv preprint arXiv: 2210.03629.
https://doi.org/10.48550/arXiv.2210.03629
|
| [18] |
Chen, X., & Zeng, A. (2024). A survey on large language model based autonomous agents. In CCL 2024-23rd Chinese Natl Conf Comput Linguist (Vol. 2, No. 6, pp. 141-150).
https://doi.org/10.1007/s11704-024-40231-1
|
| [19] |
Dong, Q., Li, L., Dai, D., Zheng, C., Ma, J., Li, R.,... & Sui, Z. (2024, November). A survey on in-context learning. In Proceedings of the 2024 conference on empirical methods in natural language processing (pp. 1107-1128).
https://doi.org/10.18653/v1/2024.emnlp-main.64
|
| [20] |
Debnath, T., Siddiky, M. N. A., Rahman, M. E., Das, P., Guha, A. K., Rahman, M. R., & Kabir, H. M. (2025). A comprehensive survey of prompt engineering techniques in large language models. TechRxiv.
https://doi.org/10.36227/techrxiv.174140719.96375390/v2
|
| [21] |
Wu, Q., Bansal, G., Zhang, J., Wu, Y., Li, B., Zhu, E.,... & Wang, C. (2024, August). Autogen: Enabling next-gen LLM applications via multi-agent conversations. In First conference on language modeling.
https://doi.org/10.48550/arXiv.2308.08155
|
| [22] |
Tran, Khanh-Tung, Nguyen, Thai-Hoang, & Nguyen, Le-Minh. (2025). Multi-agent collaboration mechanisms: A survey of LLMs. arXiv preprint arXiv: 2501.06322.
https://doi.org/10.48550/arXiv.2501.06322
|
| [23] |
Yehudai, A., Eden, L., Li, A., Uziel, G., Zhao, Y., Bar-Haim, R. & Shmueli-Scheuer, M. (2025). Survey on evaluation of llm-based agents. arXiv preprint arXiv: 2503.16416.
https://doi.org/10.48550/arXiv.2503.16416
|
| [24] |
Chase, Harrison. (2022). LangChain: Building applications with LLMs through composability. GitHub repository. Available from:
https://github.com/langchain-ai/langchain
|
| [25] |
Boda, V. V. R. (2026). Design and Implementation of a High-Availability Enterprise Data Integration System Using Automated ETL Pipelines. International Journal of AI, BigData, Computational and Management Studies, 222-231.
Available from:
https://ijaibdcms.org/index.php/ijaibdcms/article/view/414
|
| [26] |
Rawat, Manish, et al. (2025). Pre-Act: Multi-step planning and reasoning improves acting in LLM agents. arXiv preprint arXiv: 2505.09970.
https://doi.org/10.48550/arXiv.2505.09970
|
| [27] |
Devlin, Jacob, Chang, Ming-Wei, Lee, Kenton, & Toutanova, Kristina. (2019). BERT: Pre-training of deep bidirectional transformers for language understanding. Proc. NAACL-HLT, 4171-4186.
https://doi.org/10.18653/v1/N19-1423
|
| [28] |
Vaswani, Ashish, Shazeer, Noam, Parmar, Niki, Uszkoreit, Jakob, Jones, Llion, Gomez, Aidan N., Kaiser, Łukasz, & Polosukhin, Illia. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30, 5998-6008.
https://doi.org/10.48550/arXiv.1706.03762
|
| [29] |
Wei, Jason, Wang, Xuezhi, Schuurmans, Dale, Maeda, Maarten, Polozov, Oleksandr, Le, Quoc V., & Zhou, Denny. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35, 24824-24837.
https://doi.org/10.48550/arXiv.2201.11903
|
| [30] |
Lewis, Patrick, Perez, Ethan, Piktus, Aleksandra, Petroni, Fabio, Karpukhin, Vladimir, Goyal, Naman, Küttler, Heinrich, Lewis, Mike, Yih, Wen-tau, Rocktäschel, Tim, Riedel, Sebastian, & Kiela, Douwe. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems, 33, 9459-9474.
https://doi.org/10.48550/arXiv.2005.11401
|
| [31] |
Gao, Yunfan, Xiong, Yun, Gao, Xinyu, Jia, Kangning, Pan, Jinliu, Bi, Yuxi, Dai, Yi, Sun, Jianyong, & Wang, Haofen. (2023). Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv: 2312.10997.
https://doi.org/10.48550/arXiv.2312.10997
|
| [32] |
Kimball, R., & Ross, M. (2013). The data warehouse toolkit: The definitive guide to dimensional modeling. John Wiley & Sons.
https://books.google.co.jp/books?hl=zh-CN&lr=&id=4rFXzk8wAB8C&oi=fnd&pg=PR27&ots=3q9QQaY3QD&sig=nwdFsWNSJxhD5uzP7j10MnVzGQI&redir_esc=y#v=onepage&q&f=false
|
| [33] |
Linstedt, Dan, & Olschimke, Michael. (2015). Building a scalable data warehouse with Data Vault 2.0. Morgan Kaufmann.
https://www.sciencedirect.com/book/monograph/9780128025109/building-a-scalable-data-warehouse-with-data-vault-2-0
|
| [34] |
Hipp, D. Richard. (2020). SQLite: Lightweight, embedded, serverless database. SQLite Consortium. Available from:
https://www.sqlite.org/index.html
|
| [35] |
Oboe. (2026). Dialogue state tracking - Mastering conversational AI flows. Available from:
https://oboe.com/learn/mastering-conversational-ai-flows-1r2xwmz/dialogue-state-tracking-va5v1
|
Cite This Article
-
APA Style
Liu, Q., Xu, W. (2026). Carbon Agent: A Multi-Agent Framework for Oilfield Carbon Footprint Analysis via Dual-RAG and Planner-Executor. International Journal of Energy and Environmental Science, 11(2), 25-37. https://doi.org/10.11648/j.ijees.20261102.11
 Copy
|
Copy
|
 Download
Download
ACS Style
Liu, Q.; Xu, W. Carbon Agent: A Multi-Agent Framework for Oilfield Carbon Footprint Analysis via Dual-RAG and Planner-Executor. Int. J. Energy Environ. Sci. 2026, 11(2), 25-37. doi: 10.11648/j.ijees.20261102.11
Copy
|
Download
AMA Style
Liu Q, Xu W. Carbon Agent: A Multi-Agent Framework for Oilfield Carbon Footprint Analysis via Dual-RAG and Planner-Executor. Int J Energy Environ Sci. 2026;11(2):25-37. doi: 10.11648/j.ijees.20261102.11
Copy
|
Download
-
@article{10.11648/j.ijees.20261102.11,
author = {Qihang Liu and Wenjia Xu},
title = {Carbon Agent: A Multi-Agent Framework for Oilfield Carbon Footprint Analysis via Dual-RAG and Planner-Executor},
journal = {International Journal of Energy and Environmental Science},
volume = {11},
number = {2},
pages = {25-37},
doi = {10.11648/j.ijees.20261102.11},
url = {https://doi.org/10.11648/j.ijees.20261102.11},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ijees.20261102.11},
abstract = {Amid escalating global climate change and the pursuit of carbon-neutrality goals, carbon emission management and carbon footprint analysis have become central challenges in the green transition of the petroleum industry. Traditional carbon footprint accounting, however, is constrained by heterogeneous data sources, complex operational procedures, and high technical barriers for non-R&D personnel. To address these challenges, this paper proposes a lightweight multi-agent framework for oilfield carbon emission data analysis. Through natural-language interaction driven by LLM, the system integrates data access, a dual retrieval-augmented generation mechanism with Schema RAG and Document RAG, a Planner-Executor workflow, and automated report generation. Business personnel can complete intent parsing, SQL generation, statistical computation, chart rendering, and report composition through natural-language instructions. The framework is evaluated in real-world business scenarios across 13 oilfields, including basic query tasks, statistical analysis tasks, visualization generation tasks, report generation tasks, and multi-turn follow-up tasks. Experimental results show that the full system configuration, which combines Schema RAG, Planner-Executor, and Document RAG, increases the task completion rate to 93.3%, the SQL semantic consistency rate to 95.8%, and the visualization success rate to 100%, while also improving report quality and multi-turn interaction consistency. This framework lowers the technical barrier of complex data exploration, improves data processing efficiency, and provides a scalable and practical solution for the low-carbon digital transformation of the petroleum industry.},
year = {2026}
}
Copy
|
Download
-
TY - JOUR
T1 - Carbon Agent: A Multi-Agent Framework for Oilfield Carbon Footprint Analysis via Dual-RAG and Planner-Executor
AU - Qihang Liu
AU - Wenjia Xu
Y1 - 2026/04/21
PY - 2026
N1 - https://doi.org/10.11648/j.ijees.20261102.11
DO - 10.11648/j.ijees.20261102.11
T2 - International Journal of Energy and Environmental Science
JF - International Journal of Energy and Environmental Science
JO - International Journal of Energy and Environmental Science
SP - 25
EP - 37
PB - Science Publishing Group
SN - 2578-9546
UR - https://doi.org/10.11648/j.ijees.20261102.11
AB - Amid escalating global climate change and the pursuit of carbon-neutrality goals, carbon emission management and carbon footprint analysis have become central challenges in the green transition of the petroleum industry. Traditional carbon footprint accounting, however, is constrained by heterogeneous data sources, complex operational procedures, and high technical barriers for non-R&D personnel. To address these challenges, this paper proposes a lightweight multi-agent framework for oilfield carbon emission data analysis. Through natural-language interaction driven by LLM, the system integrates data access, a dual retrieval-augmented generation mechanism with Schema RAG and Document RAG, a Planner-Executor workflow, and automated report generation. Business personnel can complete intent parsing, SQL generation, statistical computation, chart rendering, and report composition through natural-language instructions. The framework is evaluated in real-world business scenarios across 13 oilfields, including basic query tasks, statistical analysis tasks, visualization generation tasks, report generation tasks, and multi-turn follow-up tasks. Experimental results show that the full system configuration, which combines Schema RAG, Planner-Executor, and Document RAG, increases the task completion rate to 93.3%, the SQL semantic consistency rate to 95.8%, and the visualization success rate to 100%, while also improving report quality and multi-turn interaction consistency. This framework lowers the technical barrier of complex data exploration, improves data processing efficiency, and provides a scalable and practical solution for the low-carbon digital transformation of the petroleum industry.
VL - 11
IS - 2
ER -
Copy
|
Download