Daily oil production forecasts are a key part of how reservoirs are managed and how production plans are made in the upstream oil and gas industry. In practice, however, getting accurate daily forecasts is not always easy. This is very common in the Niger Delta region where wells are usually affected by shutdowns, flow interruptions and changing operational conditions. Because of these reasons, oil production data from these wells are usually irregular and traditional forecasting methods usually struggle to capture these changes. This study looks at whether machine learning models can do a better job of predicting daily oil production rates. Historical oil production data from four wells in a Niger Delta oilfield was used for the study. Two ensemble models which are random forest and gradient boosting were selected and tested. Before building the models, the data was checked carefully and cleaned. Some new variables were also created to help the models understand how production changes over time. Hyperparameter optimization was performed using RandomisedSearchCV with 5-fold cross-validation to choose the best model settings and to avoid the risk of overfitting. Their performance was assessed using Coefficient of Determination (R²), Root Measure Squared Error (RMSE), and Mean Absolute Error (MAE). From the results, Gradient Boosting performed better in most cases. Its R² values were generally between 0.8767 and 0.9887, while the Random Forest model produced values in the range of about 0.7803 to 0.9756. The best predictions were obtained for wells that showed relatively stable production behaviour. For wells with frequent shutdowns and more unstable production, both models recorded higher errors with random forest having the highest error across all wells. This shows that prediction becomes more difficult when production conditions change often. Even though, the overall results suggest that ensemble machine learning models, particularly Gradient Boosting, can provide useful and reasonably accurate daily oil production forecasts for Niger Delta fields. These models can therefore support better planning and operational decision-making in Nigeria’s upstream oil and gas sector.
| Published in | Petroleum Science and Engineering (Volume 10, Issue 1) |
| DOI | 10.11648/j.pse.20261001.11 |
| Page(s) | 1-16 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2026. Published by Science Publishing Group |
Machine Learning, Random Forest, Gradient Boosting, Production Forecasting
Hyperparameter | Random Forest | Gradient Boosting |
|---|---|---|
n_estimators | 100 | 100 |
max_depth | None | 3 |
min_samples_split | 2 | 2 |
min_samples_leaf | 1 | 1 |
learning_rate | NA | 0.1 |
subsample | NA | 1.0 |
Well | Model | Hyperparameters |
|---|---|---|
1 | RF | n_estimators=300, max_depth=15, min_samples_split=2, min_samples_leaf=1 |
GB | n_estimators=300, max_depth=3, learning_rate=0.05, subsample=0.8 | |
2 | RF | n_estimators=100, max_depth=None, min_samples_split=2, min_samples_leaf=1 |
GB | n_estimators=100, max_depth=5, learning_rate=0.01, subsample=0.9 | |
3 | RF | n_estimators=200, max_depth=15, min_samples_split=5, min_samples_leaf=4 |
GB | n_estimators=100, max_depth=3, learning_rate=0.1, subsample=0.8 | |
4 | RF | n_estimators=200, max_depth=15, min_samples_split=2, min_samples_leaf=2 |
GB | n_estimators=300, max_depth=3, learning_rate=0.1, subsample=0.9 |
Well | Model | RMSE | MAE | |
|---|---|---|---|---|
Well 1 | Random Forest | 0.8508 | 25.7662 | 14.59871 |
Well 1 | Gradient Boosting | 0.9164 | 19.281 | 11.5872 |
Well 2 | Random Forest | 0.8275 | 59.2901 | 45.84983 |
Well 2 | Gradient Boosting | 0.8767 | 48.3085 | 39.9508 |
Well 3 | Random Forest | 0.7803 | 101.4342 | 56.1928 |
Well 3 | Gradient Boosting | 0.8956 | 69.9055 | 33.4839 |
Well 4 | Random Forest | 0.9756 | 26.5602 | 14.3022 |
Well 4 | Gradient Boosting | 0.9887 | 18.0494 | 7.9243 |
ANN | Artificial Neural Network |
ARIMA | Autoregressive Integrated Moving Average |
CV | Cross-Validation |
DCA | Decline Curve Analysis |
GB | Gradient Boosting |
GOR | Gas–Oil Ratio |
KNN | k-Nearest Neighbors |
Lag-n | Time Lag of n Days |
LSTM | Long Short-Term Memory |
MAE | Mean Absolute Error |
MSE | Mean Squared Error |
ML | Machine Learning |
RF | Random Forest |
RMSE | Root Mean Squared Error |
R² | Coefficient of Determination |
SVR | Support Vector Regression |
SVM | Support Vector Machine |
| [1] | Doan, T., & Van Vo, M. (2021). Using machine learning techniques for enhancing production forecast in the North Malay Basin. Proceedings of the International Field Exploration and Development Conference 2020 (pp. 114–121). Springer. |
| [2] | AlRassas, A. M., et al. (2021). Optimized ANFIS model using Aquila Optimizer for oil production forecasting. Processes, 9(7), 1194. |
| [3] | Makhotin, I., Koroteev, D., & Burnaev, E. (2019). Gradient Boosting to Boost the Efficiency of Hydraulic Fracturing. Journal of Petroleum Exploration and Production Technology. |
| [4] | Ibrahim, N. M., et al. (2022). Well performance classification and prediction: Deep learning and machine learning long-term regression experiments on oil, gas, and water production. Sensors, 22(14), 5326. |
| [5] | Negash, B. M., & Yaw, A. D. (2020). Artificial neural network-based production forecasting for a hydrocarbon reservoir under water injection. Petroleum Exploration and Development, 47(2), 383–392. |
| [6] | Arps, J. J. (1945). Analysis of Decline Curves. Transactions of the AIME, 160(1), 228–247. |
| [7] | Al-Fakih, A., Ibrahim, A. F., Elkatatny, S., & Abdulraheem, A. (2023). Estimating electrical resistivity from logging data for oil wells using machine learning. Journal of Petroleum Exploration and Production Technology, 13(6), 1453–1461. |
| [8] | Omotosho, T. J. (2024). Oil Production Prediction Using Time Series Forecasting and Machine Learning Techniques. Society of Petroleum Engineers - SPE Nigeria Annual International Conference and Exhibition, NAIC 2024. |
| [9] | Tariq, Z., Aljawad, M. S., Hasan, A., Murtaza, M., Mohammed, E., El-Husseiny, A., Alarifi, S. A., Mahmoud, M., & Abdulraheem, A. (2021). A systematic review of data science and machine learning applications to the oil and gas industry. Journal of Petroleum Exploration and Production Technology 2021 11: 12, 11(12), 4339–4374. |
| [10] | Nekekpemi, Prosper; Totaro, Michael; Olayiwola, Olatunji; Esenenjor, Pascal 2024 Development of Machine Learning Models for Predicting Bubble-Point Pressure of Crude Oils |
| [11] | Tadjer, A., Hong, A., & Bratvold, R. B. (2021). Machine learning based decline curve analysis for short-term oil production forecast. Energy Exploration and Exploitation, 39(5), 1747–1769. |
| [12] | Fan, D., Sun, H., Yao, J., Zhang, K., Yan, X., Sun, Z., 2021. Well production forecasting based on ARIMA-LSTM model considering manual operations. Energy 220, 119708. |
| [13] | Tan, C., et al. (2021). Fracturing productivity prediction model and optimization of the operation parameters of shale gas wells based on machine learning. Lithosphere, 2021(Special 4), 2884679. |
| [14] | Wang, X.-Y., Ma, Y.-J., Fei, E.-Z., & Gao, Y.-F. (2023). Daily production prediction of oil wells based on machine learning. In Proceedings of the International Conference on Automation Control, Algorithm, and Intelligent Bionics (ACAIB 2023) (Vol. 12759, pp. 516–520). SPIE. |
| [15] | Ojedapo, B., Ikiensikimama, S. S., & Wachikwu-Elechi, V. U. (2022). Petroleum Production Forecasting Using Machine Learning Algorithms. Society of Petroleum Engineers - SPE Nigeria Annual International Conference and Exhibition, NAIC 2022. |
| [16] |
Jayeola, I., Alabi, M., & Ibrahim, A. (2022). Machine Learning Prediction Versus Decline Curve Prediction: A Niger Delta Case Study. SPE Nigeria Annual International Conference and Exhibition, OnePetro.
https://onepetro.org/SPENAIC/proceedings-abstract/22NAIC/2-22NAIC/D021S009R002/495009 |
| [17] | Song, X., et al. (2024). A comprehensive review of data-driven approache Artificial Intelligence Review. |
| [18] | Adewale, M. D., Adey (Placeholder 1) anju, I. A., Oju, J., Ubadike, O. C., Muhammed, U. I., & Omisakin, S. T. (2025). Ensemble machine learning methods to predict oil production. In Innovations and Interdisciplinary Solutions for Underserved Areas (INTERSOL). Springer. |
| [19] | Shuqin Wen, Bing Wei, Junyu You, Yujiao He, Jun Xin, Mikhail A. Varfolomeev, Forecasting oil production in unconventional reservoirs using long short term memory network coupled support vector regression method: A case study, Petroleum, Volume 9, Issue 4, 2023, Pages 647-657, |
| [20] | Lee K, Lim J, Yoon D, et al. (2019) Prediction of shale-gas production at duvernay formation using deep-learning algorithm. SPE Journal 24(6): 2423–2437. |
| [21] | Ahmed Alsaihati, Mahmoud Abughaban, Salaheldin Elkatatny, and Dhafer Al Shehri Application of Machine Learning Methods in Modeling the Loss of Circulation Rate while Drilling Operation ACS Omega 2022, 7, 20696−20709. |
| [22] | Lee, J.; Wang, W.; Harrou, F.; Sun, Y. Reliable solar irradiance prediction using ensemble learning-based models: A comparative study. Energy Convers. Manag. 2020, 208, 112582. |
| [23] | Ayuba, I., Akanji, L. T., & Gomes, J. (2025). Numerical quantification of gas adsorption in unconventional shale rocks. Fuel, 396, 135246. |
| [24] | Ayuba, I., Akanji, L. T., Gomes, J. L., & Falade, G. K. (2021). Investigation of drift phenomena at the pore scale during flow and transport in porous media. Mathematics, 9(19), 2509. |
| [25] | Salisu, A. M., Ayuba, I., Abdulrasheed, A., & Usman, A. (2025). Predicting liquid loading in gas condensate wells using machine learning to enhance production efficiency. Petroleum Science and Engineering, 9(2), 55–66 |
| [26] | Maharana K, Mondal S, Nemade B. A review: Data pre-processing and data augmentation techniques. Global Transitions Proceedings. 2022 Jun 1; 3(1): 91-9. |
| [27] | Suherman IC, Sarno R. Implementation of random forest regression for COCOMO II effort estimation. In 2020 international seminar on application for technology of information and communication (iSemantic) 2020 Sep 19 (pp. 476-481). IEEE. |
| [28] | Yilmazer S, Kocaman S. A mass appraisal assessment study using machine learning based on multiple regression and random forest. Land use policy. 2020 Dec 1; 99: 104889. |
| [29] | A. Jain, H. Patel, L. Nagalapatti, N. Gupta, S. Mehta, S. Guttula, S. Mujumdar, S. Afzal, R. Sharma Mittal and V. Munigala Overview and importance of data quality for machine learning tasks. InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining 2020 Aug 23 (pp. 3561–3562). |
| [30] | Garcia-Carretero R, Holgado-Cuadrado R, Barquero-Pérez Ó. Assessment of classification models and relevant features on nonalcoholic steatohepatitis using random forest. Entropy. 2021 Jun 17; 23(6): 763. |
| [31] | Adeniyi EA, Gbadamosi B, Awotunde JB, Misra S, Sharma MM, Oluranti J (2022) Crude Oil Price Prediction Using Particle Swarm Optimization and Classi?cation Algorithms. 418 LNNS, 1384–1394. Scopus. |
| [32] | Moroff, N. U., Kurt, E., & Kamphues, J. (2021). Machine learning and statistics: A study for assessing innovative demand forecasting models. Procedia Computer Science, 180, 40–49. |
| [33] | Schuetter J., Mishra S., Zhang M. and Lafollette R. (2015). Data Analytics for Production Optimization in Unconven- tional Reservoirs presented at Unconventional Resources Technology Conference, San Antonio, Texas, USA 2015. |
| [34] | Shumway, R. and D. Stoffer. “Time Series Analysis and Its Applications: With R Examples.” ser. Springer Texts in Statistics. Springer New York, 2010. Available: |
| [35] | Niu, W.; Lu, J.; Sun, Y. A Production Prediction Method for Shale Gas Wells Based on Multiple Regression. Energies 2021, 14, 1461. |
| [36] | G. S. Ohannesian and E. J. Harfash, "Epileptic Seizures Detection from EEG Recordings Based on a Hybrid system of Gaussian Mixture Model and Random Forest Classifier," Informatica, vol. 46, no. 6, 2022, |
| [37] | Friedman, J. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. |
| [38] | Mo, H., Sun, H., Liu, J., & Wei, S. (2019). Developing window behavior models for residential buildings using XGBoost algorithm. Energy and Buildings, 205, 109564. |
| [39] | Alqahtani MG, Abdelhafez HA (2023) STOCK MARKET PREDICITION USING STATISTICAL & DEEP LEARNING TECHNIQUES. J Theoretical Appl Inform Technology 101(23): 7808–7825 Scopus. |
| [40] | Chicco, D., Warrens, M. J., & Jurman, G. (2021). The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Computer Science, 7, e623. |
| [41] | Dennis A. Huber, Jacob N. Persson, Forecasting Volatility: Evidence From The Swiss Stock Market. Master thesis at Lund university School of Economics and Managements 2010. |
| [42] | Eva Elling and Hannes Fornander, A Study of Recommender Techniques Within the Field of Collaborative Filtering. Thesis at KTH, School of Electrical Engineering, 2017. |
| [43] | Abbaszadeh M, Soltani-Mohammadi S, Ahmed AN. Optimization of support vector machine parameters in modeling of Iju deposit mineralization and alteration zones using particle swarm optimization algorithm and grid search method. Computers & Geosciences. 2022 Aug 1; 165: 105140. |
| [44] | Abbas MA, Al-Mudhafar WJ, Wood DA. Improving permeability prediction in carbonate reservoirs through gradient boosting hyperparameter tuning. Earth Science Informatics. 2023 Dec; 16(4): 3417-32. |
| [45] | Sandunil K, Bennour Z, Ben Mahmud H, Giwelli A. Effects of Tuning Hyperparameters in Random Forest Regression on Reservoir's Porosity Prediction. Case Study: Volve Oil Field, North Sea. InARMA US Rock Mechanics/Geomechanics Symposium 2023 Jun 25 (pp. ARMA-2023). ARMA. |
| [46] | Tao, Y. and Du, J. (2019) Temperature prediction using long short term memory network based on Random Forest [J]. Computer Engineering and Design, 40(03), 737-743. |
| [47] | Shen, P., Jin, Q., Zhou, Y., Xu, R. and Huang, H. (2022) Spatial-temporal pattern and driving factors of surface ozone concentrations in Zhejiang Province [J]. Research of Environmental Sciences, 35(09), 2136-2146. |
| [48] | Rimal Y, Sharma N, Alsadoon A (2024) The accuracy of machine learning models relies on hyperparameter tuning: student result classification using random forest, randomized search, grid search, bayesian, genetic, and optuna algorithms. Multimedia Tools Appl 83(30): 74349–74364. |
| [49] | Liu, D.; Sun, K. Random forest solar power forecast based on classification optimization. Energy 2019, 187, 115940.1–115940.11. |
| [50] | Tianrui Cai Stock Forecasting Based on Random Forest and ARIMA Models Proceedings of CONF-MPCS 2025 Symposium: Mastering Optimization: Strategies for Maximum Efficiency |
| [51] | Hyndman, R. J., & Athanasopoulos, G. (2018) Forecasting: principles and practice, 2nd edition, OTexts: Melbourne, Australia. OTexts.com/fpp2 |
| [52] | Haseen. Forecasting Crude Oil Prices: Insights from Machine Learning Approaches, 16 December 2025, PREPRINT (Version 1) available at Research Square |
APA Style
Haliru, H. K., Ashurah, S. A., Ayuba, I. (2026). Application of Machine Learning for Production Forcasting in Niger Delta Oil Field (Ozoro Field). Petroleum Science and Engineering, 10(1), 1-16. https://doi.org/10.11648/j.pse.20261001.11
ACS Style
Haliru, H. K.; Ashurah, S. A.; Ayuba, I. Application of Machine Learning for Production Forcasting in Niger Delta Oil Field (Ozoro Field). Pet. Sci. Eng. 2026, 10(1), 1-16. doi: 10.11648/j.pse.20261001.11
@article{10.11648/j.pse.20261001.11,
author = {Haliru Kawule Haliru and Shamsuddeen Abubakar Ashurah and Ibrahim Ayuba},
title = {Application of Machine Learning for Production Forcasting in Niger Delta Oil Field (Ozoro Field)},
journal = {Petroleum Science and Engineering},
volume = {10},
number = {1},
pages = {1-16},
doi = {10.11648/j.pse.20261001.11},
url = {https://doi.org/10.11648/j.pse.20261001.11},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.pse.20261001.11},
abstract = {Daily oil production forecasts are a key part of how reservoirs are managed and how production plans are made in the upstream oil and gas industry. In practice, however, getting accurate daily forecasts is not always easy. This is very common in the Niger Delta region where wells are usually affected by shutdowns, flow interruptions and changing operational conditions. Because of these reasons, oil production data from these wells are usually irregular and traditional forecasting methods usually struggle to capture these changes. This study looks at whether machine learning models can do a better job of predicting daily oil production rates. Historical oil production data from four wells in a Niger Delta oilfield was used for the study. Two ensemble models which are random forest and gradient boosting were selected and tested. Before building the models, the data was checked carefully and cleaned. Some new variables were also created to help the models understand how production changes over time. Hyperparameter optimization was performed using RandomisedSearchCV with 5-fold cross-validation to choose the best model settings and to avoid the risk of overfitting. Their performance was assessed using Coefficient of Determination (R²), Root Measure Squared Error (RMSE), and Mean Absolute Error (MAE). From the results, Gradient Boosting performed better in most cases. Its R² values were generally between 0.8767 and 0.9887, while the Random Forest model produced values in the range of about 0.7803 to 0.9756. The best predictions were obtained for wells that showed relatively stable production behaviour. For wells with frequent shutdowns and more unstable production, both models recorded higher errors with random forest having the highest error across all wells. This shows that prediction becomes more difficult when production conditions change often. Even though, the overall results suggest that ensemble machine learning models, particularly Gradient Boosting, can provide useful and reasonably accurate daily oil production forecasts for Niger Delta fields. These models can therefore support better planning and operational decision-making in Nigeria’s upstream oil and gas sector.},
year = {2026}
}
TY - JOUR T1 - Application of Machine Learning for Production Forcasting in Niger Delta Oil Field (Ozoro Field) AU - Haliru Kawule Haliru AU - Shamsuddeen Abubakar Ashurah AU - Ibrahim Ayuba Y1 - 2026/02/24 PY - 2026 N1 - https://doi.org/10.11648/j.pse.20261001.11 DO - 10.11648/j.pse.20261001.11 T2 - Petroleum Science and Engineering JF - Petroleum Science and Engineering JO - Petroleum Science and Engineering SP - 1 EP - 16 PB - Science Publishing Group SN - 2640-4516 UR - https://doi.org/10.11648/j.pse.20261001.11 AB - Daily oil production forecasts are a key part of how reservoirs are managed and how production plans are made in the upstream oil and gas industry. In practice, however, getting accurate daily forecasts is not always easy. This is very common in the Niger Delta region where wells are usually affected by shutdowns, flow interruptions and changing operational conditions. Because of these reasons, oil production data from these wells are usually irregular and traditional forecasting methods usually struggle to capture these changes. This study looks at whether machine learning models can do a better job of predicting daily oil production rates. Historical oil production data from four wells in a Niger Delta oilfield was used for the study. Two ensemble models which are random forest and gradient boosting were selected and tested. Before building the models, the data was checked carefully and cleaned. Some new variables were also created to help the models understand how production changes over time. Hyperparameter optimization was performed using RandomisedSearchCV with 5-fold cross-validation to choose the best model settings and to avoid the risk of overfitting. Their performance was assessed using Coefficient of Determination (R²), Root Measure Squared Error (RMSE), and Mean Absolute Error (MAE). From the results, Gradient Boosting performed better in most cases. Its R² values were generally between 0.8767 and 0.9887, while the Random Forest model produced values in the range of about 0.7803 to 0.9756. The best predictions were obtained for wells that showed relatively stable production behaviour. For wells with frequent shutdowns and more unstable production, both models recorded higher errors with random forest having the highest error across all wells. This shows that prediction becomes more difficult when production conditions change often. Even though, the overall results suggest that ensemble machine learning models, particularly Gradient Boosting, can provide useful and reasonably accurate daily oil production forecasts for Niger Delta fields. These models can therefore support better planning and operational decision-making in Nigeria’s upstream oil and gas sector. VL - 10 IS - 1 ER -
Department of Petroleum Engineering, Abubakar Tafawa Balewa University, Bauchi, Nigeria
Department of Petroleum Engineering, Abubakar Tafawa Balewa University, Bauchi, Nigeria
Department of Petroleum Engineering, Abubakar Tafawa Balewa University, Bauchi, Nigeria
Figure 1. Feature Engineering Illustration.
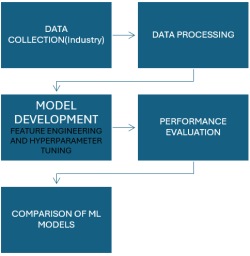
Figure 2. Methodology Workflow.
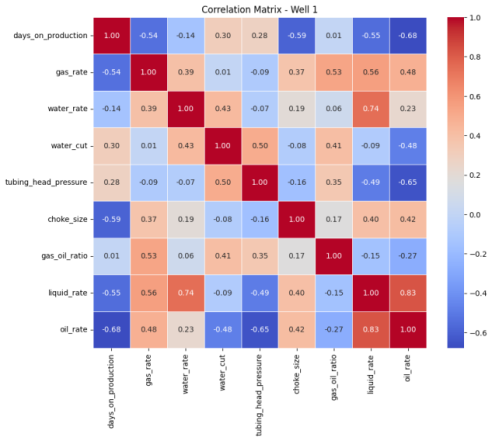
Figure 3. Pearson’s Correlation Matrix Heat Map for Well 1.
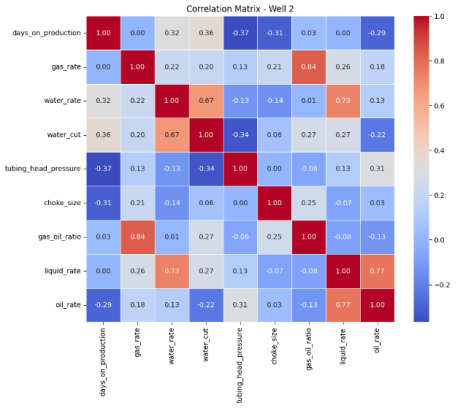
Figure 4. Pearson’s Correlation Matrix Heat Map for Well 2.
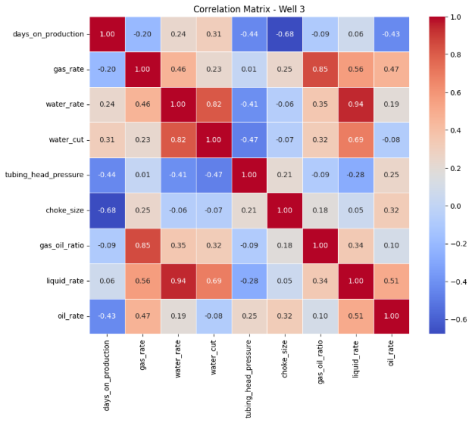
Figure 5. Pearson’s Correlation Matrix Heat Map for Well 3.
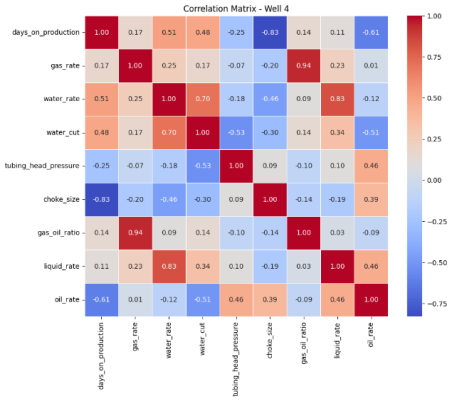
Figure 6. Pearson’s Correlation Matrix Heat Map for Well 4.
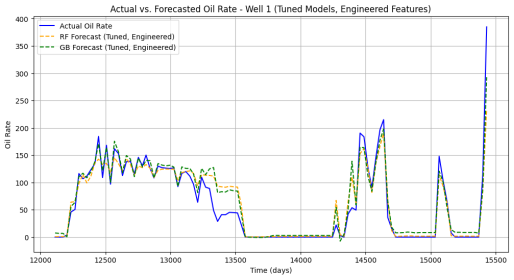
Figure 7. Actual vs. Forecasted (RF and GB) Oil Rate for Well 1.
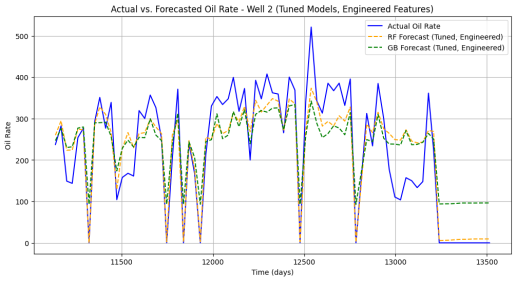
Figure 8. Actual vs. Forecasted (RF and GB) Oil Rate for Well 2.
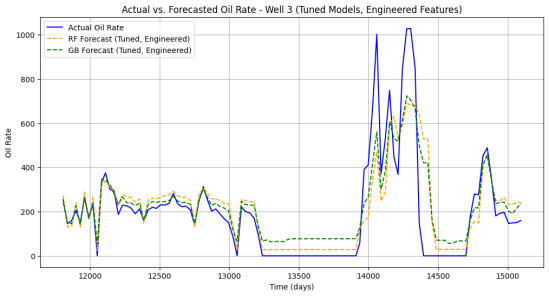
Figure 9. Actual vs. Forecasted (RF and GB) Oil Rate for Well 3.
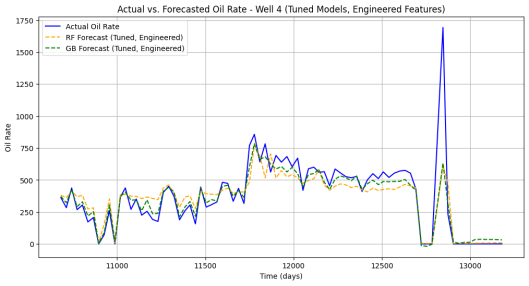
Figure 10. Actual vs. Forecasted (RF and GB) Oil Rate Well 4.
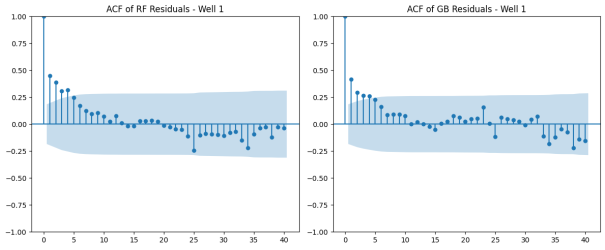
Figure 11. Autocorrelation function (ACF) of Residuals – Well 1.
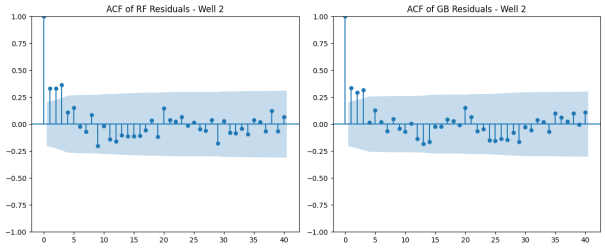
Figure 12. Autocorrelation function (ACF) of Residuals – Well 2.
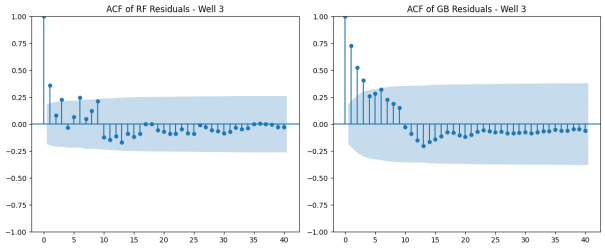
Figure 13. Autocorrelation function (ACF) of Residuals – Well 3.
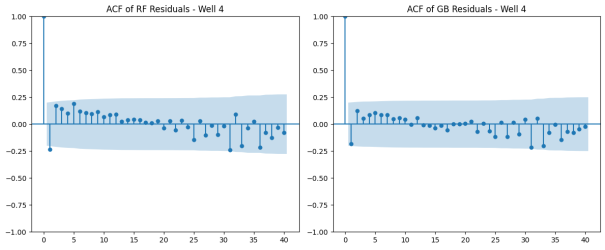
Figure 14. Autocorrelation function (ACF) of Residuals – Well 4.
Information

